
 手机网站
手机网站
手机网站
手机网站
有时候我们可以利用hive来生成统计的中间文件(比源文件小的多的)方法有如下2种: www.2cto.com 1.INSERT OVERW. 首页 数据库 其他综合 正文 hive导出查询文件到本地文件

hive读取hdfs文件-spark hbase 实时查询_hive
1080x810 - 88KB - JPEG

hive读取hdfs文件-spark hbase 实时查询_hive
600x355 - 104KB - PNG

hive读取hdfs文件-spark hbase 实时查询_hive
600x348 - 12KB - JPEG

【组图】这本读心术秘籍,我看的心服口服!,读心
600x319 - 18KB - JPEG
hive csv文件导入hive第一个字段内容为NULL--
300x356 - 31KB - JPEG
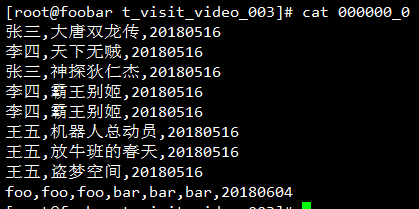
Hive笔记之导出查询结果
419x209 - 13KB - PNG

Replicating Hive Data Into Oracle BI Cloud Ser
550x268 - 80KB - PNG
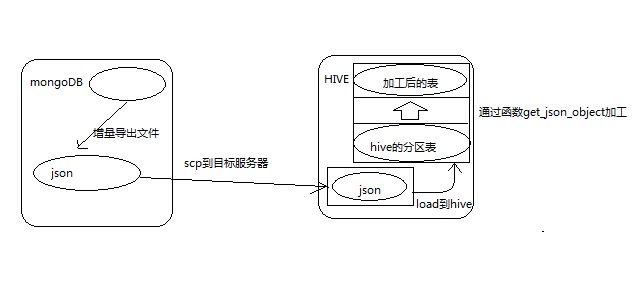
mongoDB同步数据到hive
643x293 - 30KB - JPEG

导入作业数据集total.csv到Hive中,用日期做为分
1031x655 - 881KB - JPEG

parkSQL and Pandas to Import Data into Hive
550x541 - 106KB - PNG

Hive导入10G数据的测试_「电脑玩物」中文网
617x418 - 18KB - JPEG
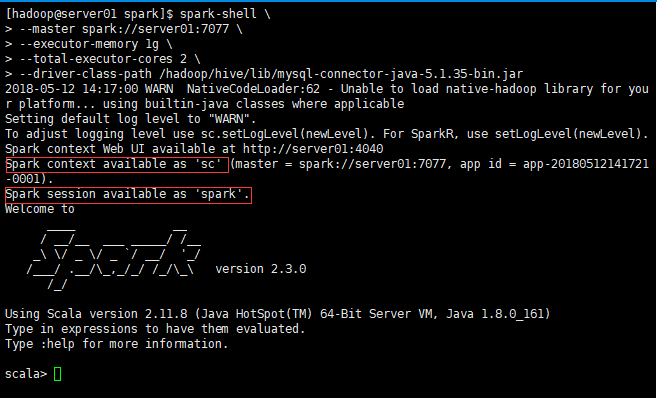
SparkSql中DataFrame与json、csv、mysql、h
657x398 - 29KB - PNG

Hive导入10G数据的测试_「电脑玩物」中文网
617x213 - 23KB - JPEG

HData首页、文档和下载 - ETL数据导入\/导出工
410x319 - 61KB - PNG
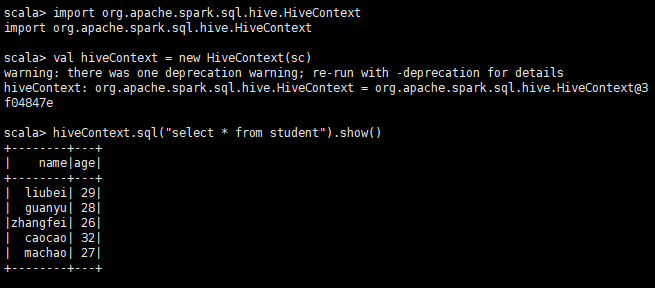
SparkSql中DataFrame与json、csv、mysql、h
655x288 - 15KB - PNG
