
 手机网站
手机网站
手机网站
手机网站
如果要让Spark读取HBase,就需要使用SparkContext提供的newAPIHadoopRDD API将表的内容以RDD的形式加载到Spark中。 请在Linux系统中打开一个终端,然后执行以下命

如何提高spark批量读取HBase数据的性能
700x525 - 74KB - JPEG
Spark读写Hbase的二种方式对比 - 今日头条(w
640x458 - 34KB - JPEG
Spark读写Hbase的二种方式对比 - 今日头条(w
640x430 - 35KB - JPEG
Spark读写Hbase的二种方式对比 - 今日头条(w
640x426 - 74KB - JPEG

hive读取hdfs文件-spark hbase 实时查询_hive
1080x810 - 88KB - JPEG

如何提高spark批量读取HBase数据的性能
320x240 - 11KB - JPEG
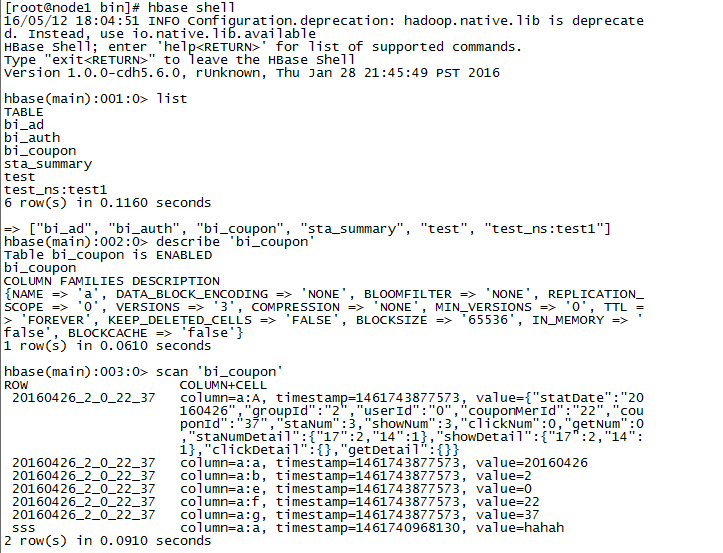
Spark读取HBase内容_Java
723x553 - 51KB - PNG
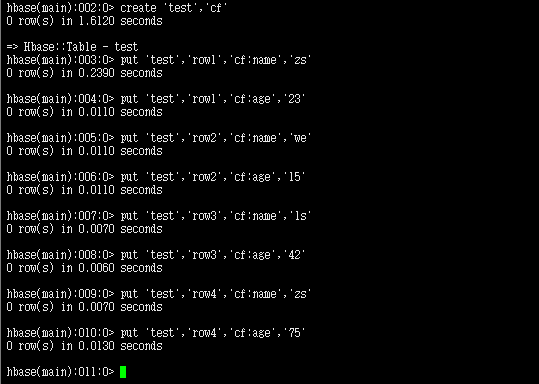
Spark连接HBase进行读写相关操作
539x384 - 15KB - PNG

Spark On Hbase_NoSQL_第七城市
400x323 - 62KB - PNG
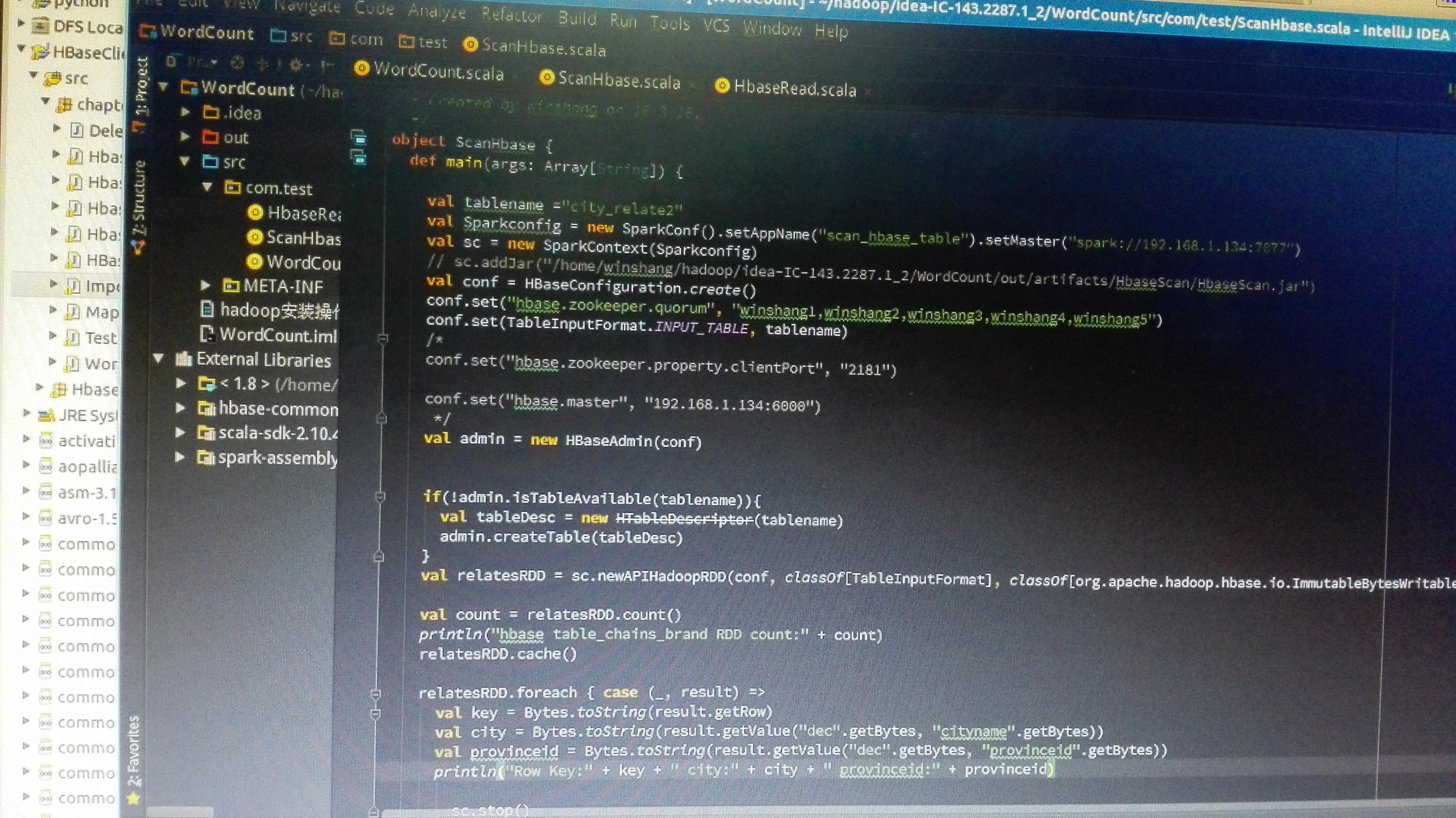
Spark submit 读取Hbase数据报错 Application
4160x2336 - 4072KB - JPEG

Spark读取hbase表的六种方式
854x545 - 53KB - PNG

Spark读取hbase表的六种方式
832x492 - 68KB - PNG

Spark读写Hbase中的数据
837x305 - 43KB - PNG

spark-shell 读写hdfs 读写hbase 读写redis - 猿类
937x558 - 18KB - PNG
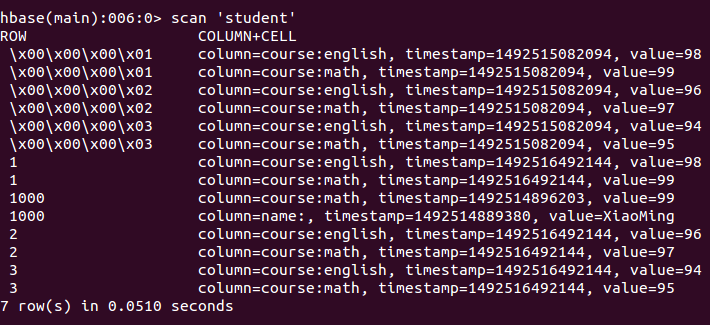
Spark学习笔记--读写Hbase - LinTong-common
710x325 - 74KB - PNG
