
 手机网站
手机网站
手机网站
手机网站
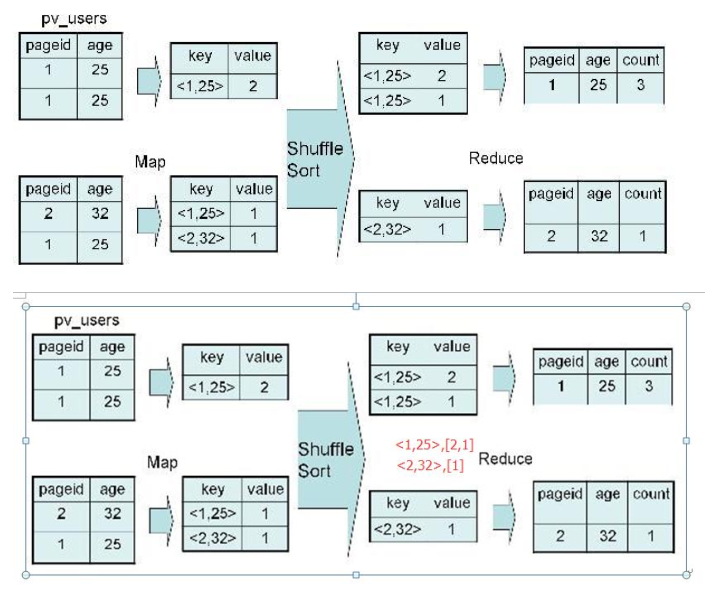
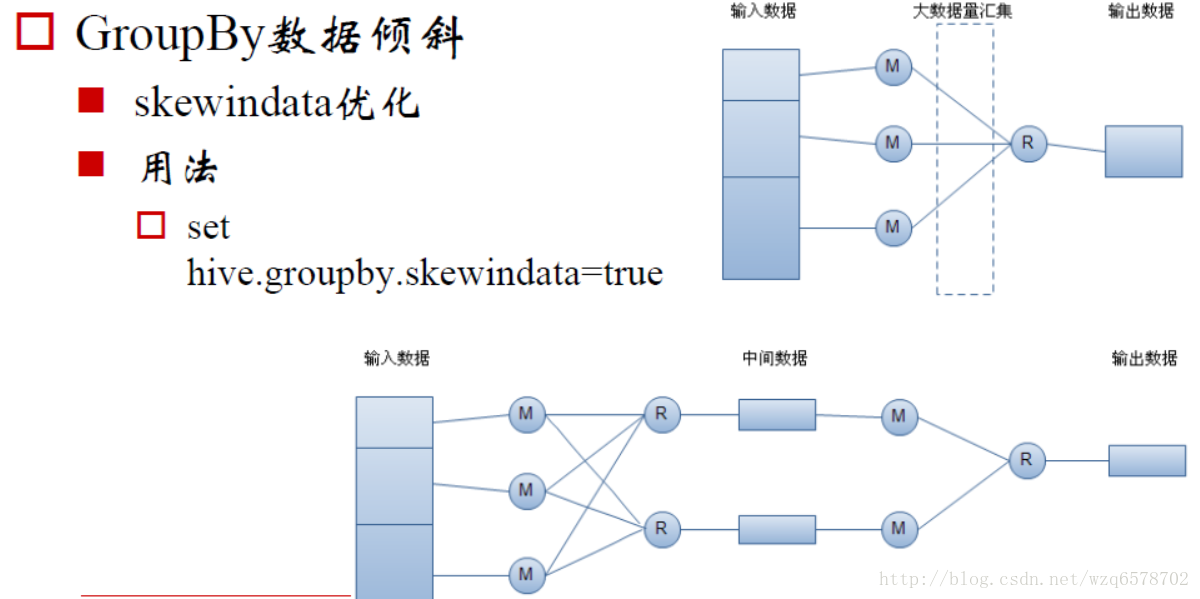
准备数据 [代码片段] [代码片段]计算过程默认设置了hive.map.aggr=true,所以会在mapper端先group by一次,最后再把结果merge起来,为了减少reducer处理的数据量。注意看exp
大数据Spark 蘑菇云行动第89课:Hive中Grou
1179x624 - 518KB - PNG

大数据Spark 蘑菇云行动第89课:Hive中Grou
1001x588 - 507KB - PNG
大数据Spark 蘑菇云行动第89课:Hive中Grou
1098x539 - 440KB - PNG

大数据Spark 蘑菇云行动第89课:Hive中Grou
950x566 - 514KB - PNG

大数据Spark 蘑菇云行动第89课:Hive中Grou
852x469 - 397KB - PNG

大数据Spark 蘑菇云行动第89课:Hive中Grou
375x351 - 134KB - PNG

hive sql优化-join Mapjoin Group by - 曾晓森的博
150x150 - 28KB - PNG

【大数据微课回顾】杨卓荦:Hive原理及查询优化
1090x408 - 44KB - JPEG

【大数据微课回顾】杨卓荦:Hive原理及查询优化
1280x489 - 35KB - JPEG
Hive(六)hive执行过程实例分析与hive优化策略
720x593 - 290KB - PNG
hive原理与源码分析-算子Operators及查询优化
1200x599 - 136KB - PNG
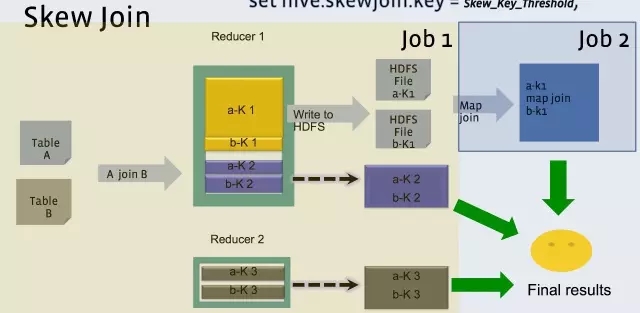
Hive原理及查询优化
640x313 - 71KB - JPEG
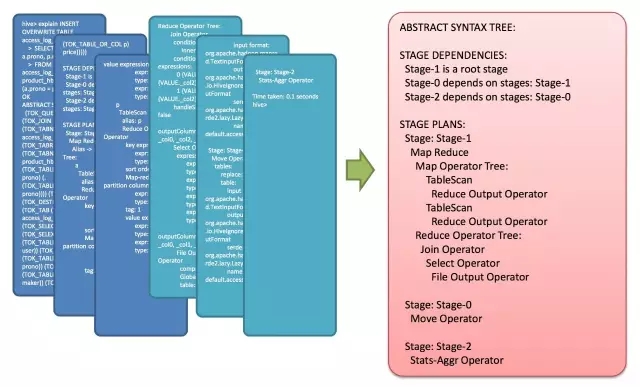
Hive原理及查询优化
640x387 - 131KB - JPEG
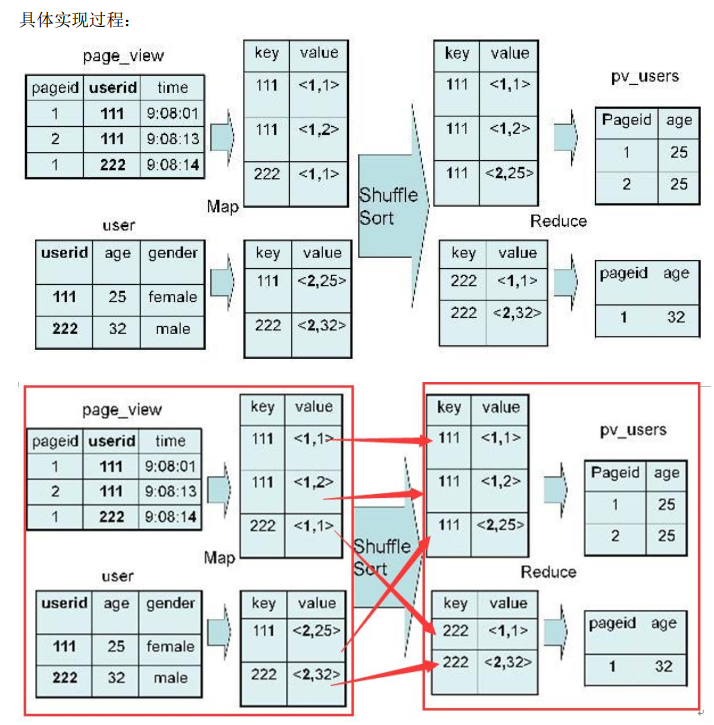
Hive(六)hive执行过程实例分析与hive优化策略
714x725 - 428KB - PNG
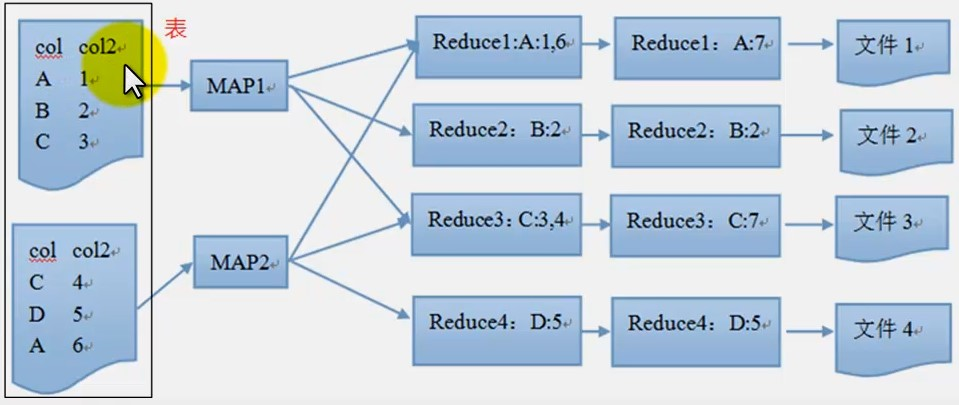
hive基础-高级查询 - zhangshihai1232
959x405 - 359KB - PNG
