
 手机网站
手机网站
手机网站
手机网站
准备数据 [代码片段] [代码片段]计算过程默认设置了hive.map.aggr=true,所以会在mapper端先group by一次,最后再把结果merge起来,为了减少reducer处理的数据量。注意看exp

Hive mapreduce SQL实现原理--SQL最终分解为
948x431 - 63KB - PNG

Hive mapreduce SQL实现原理--SQL最终分解为
907x420 - 60KB - PNG

Hive mapreduce SQL实现原理--SQL最终分解为
929x405 - 46KB - PNG

Hive mapreduce SQL实现原理--SQL最终分解为
659x289 - 32KB - PNG
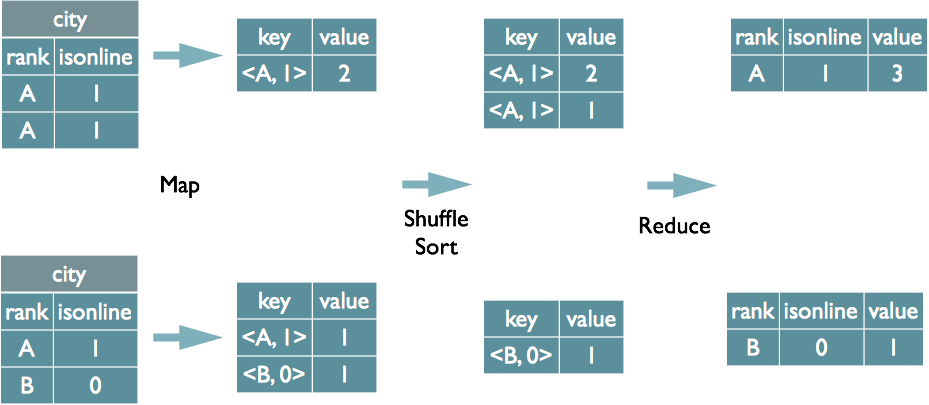
Hive SQL 编译过程详解 - leejun_2005的个人页
929x405 - 46KB - PNG

Hive SQL的编译过程 - 美团技术团队
929x405 - 46KB - PNG

hive sql语句执行原理
896x422 - 319KB - PNG

hive sql语句执行原理
663x457 - 250KB - PNG

hive sql语句执行原理
699x358 - 259KB - PNG

hive sql语句执行原理
514x281 - 137KB - PNG

Flume+Spark+Hive+Spark SQL离线分析系统_
2352x1204 - 270KB - JPEG

EMC讲解Hawq SQL:左手Hive右手Impala
500x285 - 38KB - JPEG
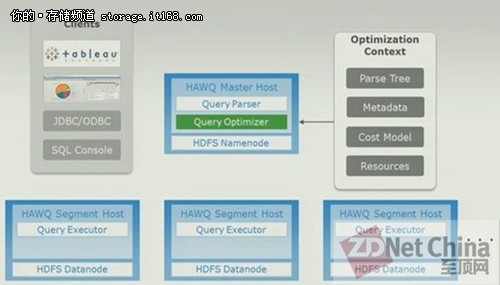
EMC讲解Hawq SQL:左手Hive右手Impala
500x285 - 38KB - JPEG

前世今生:Hive、Shark、spark SQL - 过雁
466x581 - 48KB - JPEG
Shark, Spark SQL, Hive on Spark, 及SQL 在Sp
690x465 - 34KB - JPEG
