
 手机网站
手机网站
手机网站
手机网站
和平常开发spark的application一样,开始查看API,编码,调试,验证结果。由于之前对spark的API使用过,知道API中的sortByKey()可以自定义排序规则,通过实现自定义的排序规则来

Hadoop和Spark分别实现二次排序
881x761 - 30KB - PNG

Hadoop和Spark分别实现二次排序
853x772 - 27KB - PNG

SparkAPI编程动手实战03以在Spark1.2版本实
1496x611 - 35KB - PNG

SparkAPI编程动手实战03以在Spark1.2版本实
1489x646 - 15KB - PNG

3.以在Spark 1.0.2中实现对Job输出结果进行排
668x291 - 66KB - JPEG

3.以在Spark 1.0.2中实现对Job输出结果进行排
593x326 - 71KB - JPEG

Spark SQL 之 Join 实现 - 酷辣虫 - CoLaBug.co
1202x540 - 123KB - PNG
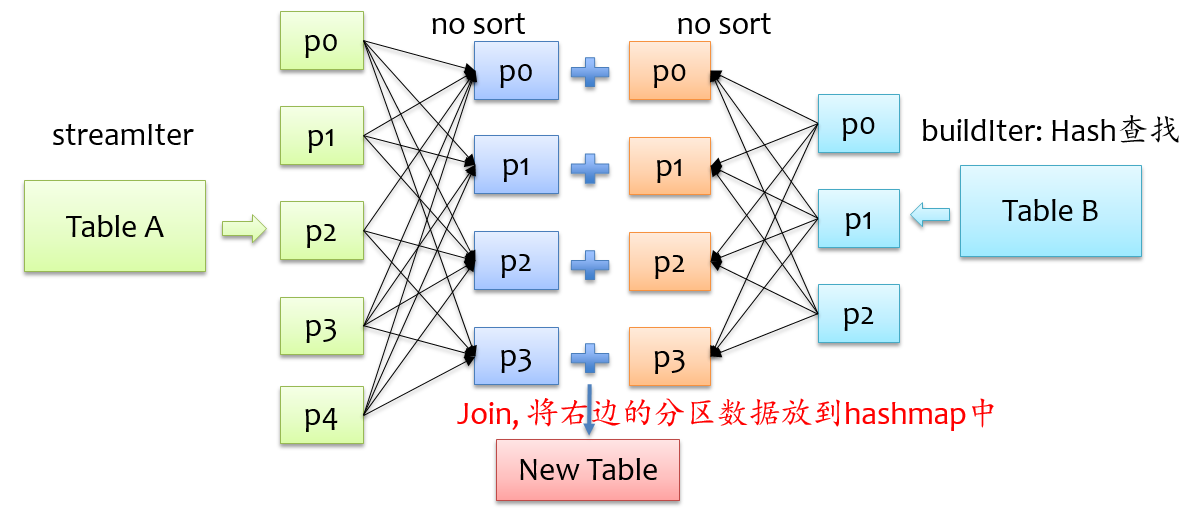
Spark SQL 之 Join 实现 - 苏轶然
1202x520 - 127KB - PNG

大数据:Spark 算子(一)排序算子sortByKey来看
680x526 - 71KB - JPEG

Hadoop&Spark解决二次排序问题_「电脑玩物
640x400 - 69KB - JPEG

Hadoop&Spark解决二次排序问题_「电脑玩物
639x476 - 23KB - JPEG
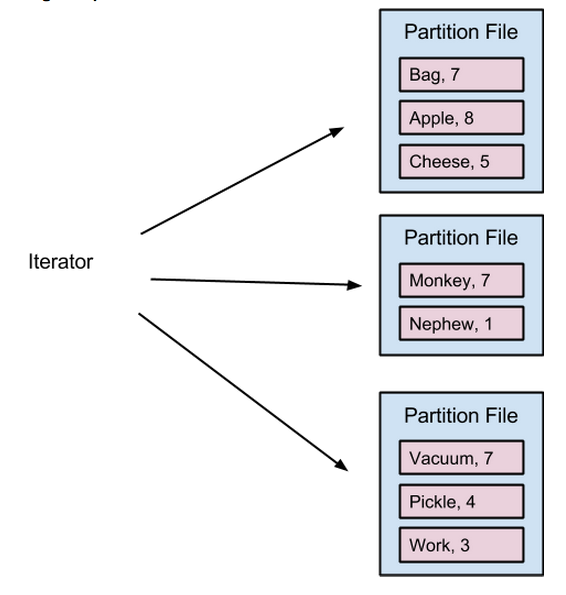
双倍提升Apache Spark排序性能
566x595 - 67KB - PNG

阿里云远超 Spark,取得四个全球排序基准竞赛
668x409 - 129KB - JPEG

计算届的奥运会 阿里云把Hadoop、Spark给秒
600x352 - 55KB - JPEG

基于Spark 2.0 机器学习之推荐系统实现
900x401 - 21KB - PNG
