
 手机网站
手机网站
手机网站
手机网站
在实际业务场景下,经常会遇到在Hive、MapReduce、Spark中需要生成唯一的数值型ID。一般常用的做法有: MapReduce中使用1个Reduce来生成; Hive中使用row_number分析

丨大数据分析专题Hadoop\/MapReduce\/Hive原
506x272 - 6KB - JPEG
丨大数据分析专题Hadoop\/MapReduce\/Hive原
600x336 - 17KB - JPEG

Hive mapreduce SQL实现原理--SQL最终分解为
929x405 - 46KB - PNG

Hive mapreduce SQL实现原理--SQL最终分解为
907x420 - 60KB - PNG

Hive mapreduce SQL实现原理--SQL最终分解为
948x431 - 63KB - PNG

Hive mapreduce SQL实现原理--SQL最终分解为
659x289 - 32KB - PNG
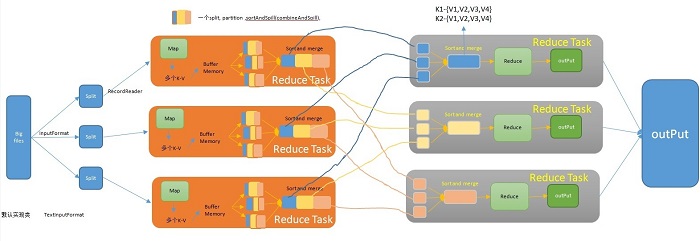
详解Hadoop核心架构HDFS+MapReduce+Hba
700x241 - 49KB - JPEG

安装Hive遇到的疑问,和对MapReduce工作原理
1014x1513 - 327KB - JPEG

hive架构原理简析-地图reduce部分
529x349 - 57KB - JPEG

【大数据微课回顾】杨卓荦:Hive原理及查询优
1280x489 - 35KB - JPEG

【大数据微课回顾】杨卓荦:Hive原理及查询优
1280x794 - 79KB - JPEG
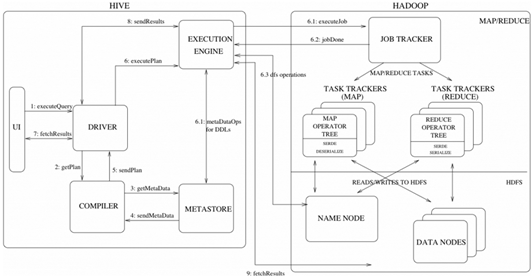
初步认识Hive - 好记性不如烂笔头!
532x279 - 94KB - PNG

【大数据微课回顾】杨卓荦:Hive原理及查询优
1280x809 - 58KB - JPEG

红黑联盟Hive
1024x530 - 208KB - PNG

【大数据微课回顾】杨卓荦:Hive原理及查询优
1280x564 - 49KB - JPEG
