
 手机网站
手机网站
手机网站
手机网站
最近,因为工作需要,需要获取天猫某一商品的全部评论数据。于是,写了一个python脚本,自动爬取所有评论。做个记录。
一、准备阶段
天猫的评论数据一般会放在JS文件里,故我们只需要打开商品页,快捷键Fn+F12,选择NetWork,筛选JS文件,找到名称为“rate.tmall....”开头的文件。
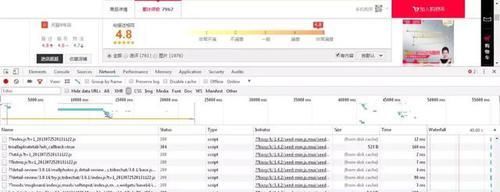
复制JS文件的链接,在新的页面打开访问。

bingo!就是我们需要的评论数据。
二、python代码

2.生成链接列表

3.获取评论数据的函数
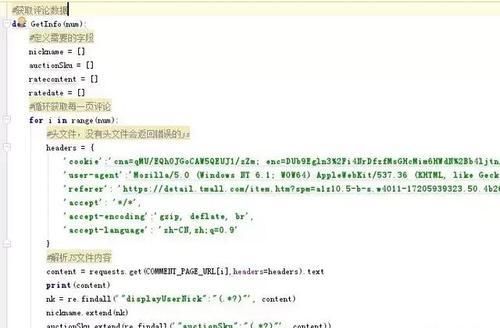
4.将爬下来的数据写入到txt文件中

5.主函数,开始运行

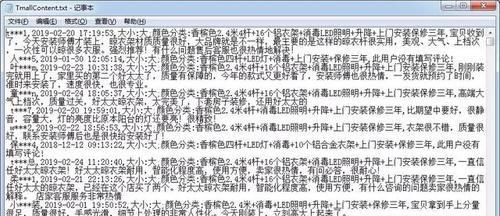
6.最终得到一个txt文件, 打开后有完整的数据,如果有需要可以导入到csv或者excel文件里。
三、遇到的坑及解决方案
四、后续操作
因为淘宝天猫取消了差评的筛选,所以我们是无法直接分类出哪些评论是差评。但是通过一些中文文本挖掘库(比如snownlp)进行购物评论文本情感分析,可以对评论进行语义分析。时间有限,后续再说。
五、获取源代码?
如何获取源代码:
