
 手机网站
手机网站
手机网站
手机网站

1.引用
Rahman M M, Roy C K, Lo D, et al. RACK: code search in the IDE using crowdsourced knowledge[C]. international conference on software engineering, 2017: 51-54
2.摘要
传统的代码搜索引擎通常不能很好地处理自然语言查询,因为它们主要应用的是关键字匹配。这些引擎为了能够检索代码,需要在查询中包含精心设计的代码API信息。不幸的是,现有的研究表明,为代码搜索准备一个有效的查询对开发人员来说既有挑战性又耗时。在这篇文章中,我们提出了一种新的代码搜索工具—RACK,这个工具以自然语言文本作为输入,返回与给定代码查询相关的源码。该工具首先将查询转换为成一个相关API的列表,该步骤通过挖掘Stack Overflow的众包知识以获得关键词-API关系(keyword-API associations)来实现;然后将重新构建后的查询作为GitHub code search API的输入来检索源码片段。一旦提交了与编程任务相关的查询,该工具就会自动从数千个开源项目中挖掘出相关的代码片段,并以一个排序列表的方式显示在开发人员的编程环境IDE的上下文中。
工具页面: http://homepage.usask.ca/~masud.rahman/rack/
索引术语—代码搜索、查询重构、关键字-API关联、众包知识、Stack Overflow
3.技术介绍 3.1 RACK 技术特性
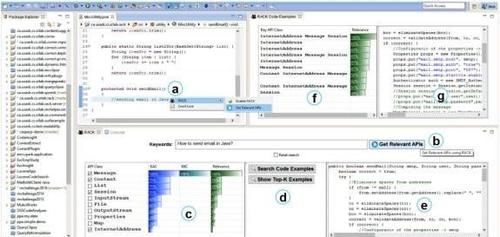
图1显示了RACK的用户界面,其中界面的(b)-(c)为查询建议面板、(d)-(e)为代码搜索面板、(f)-(g)是结果面板。
本节讨论我们的工具提供的不同技术特性。
(1)代码搜索查询的自动建议:
由于为编程任务准备一个有效的查询是一个重大挑战,RACK自动提供代码搜索的相关关键字(即,API类)的建议[5,6]。我们的工具通过从Stack Overflow Q & A 站点挖掘成千上万个编程问题及其相应的解决方案来克服这一挑战。它从IDE中的各种工作环境中捕获开发人员的代码搜索意图,并为代码搜索提供一个合适的关键字列表,这些关键字具有有意义的见解(即相关性分数)(relevance scores)。
(i)工作环境: RACK从开发人员源代码注释和传统搜索框的两个工作环境中捕获代码搜索的自然语言查询(即开发人员的意图)。一旦开发人员打算通过在一个方法的标题注释中陈述来完成一个编程任务,我们的工具就将注释捕获为一个用于重构的初始查询(例如,图1-(a))。在第二种情况下,开发人员提供一个使用非结构化自然语言文本编写的初始查询,RACK从传统搜索框(图1-(b))中捕获查询,以获得相关的API建议。
(ii)挖掘相关API类: 在Stack Overflow中,用户经常提交聚焦于编程任务的问题(例如,“我如何生成MD5哈希?”),并且相应的答案建议相关的API(如,MessageDigest)完成这些任务。RACK访问了344K个这样的问题和答案的数据库,学习关键字-API关系(keyword-API associations),然后为给定的任务建议API类
(iii)API建议和查询重构: 一旦提交了自然语言查询(即初始查询),RACK就为查询中的任务建议前10个相关的API类(图1-(c))。这些建议不仅以排名列表的形式提供,而且我们的工具通过可视化三个有意义的分数来解释为什么一个特定的API是相关的——Keyword-API Co-occurrence (KAC), Keyword-Keyword Coherence (KKC), 以及 Overall Relevance [8]。有了这样的排名和见解,开发人员可以通过标记检查过的APIs并启动代码搜索来轻松选择合适的APIs。
(2)基于IDE的代码搜索(IDE-Based Code Search): RACK不仅提供了基于IDE的代码搜索功能,还以定制的视图帮助开发人员进行结果分析。它提供了两个灵活的代码搜索选项,并在IDE中以有意义的见解(即相关性分数 relevance scores)显示结果。
(i)代码搜索选项和后端: RACK提供了两个选项-Top-1搜索和Top-K搜索,用于在IDE中执行代码搜索(图1-(d))。一旦相关的API类被建议(由工具)并且开发人员选择了合适的类(即,搜索关键字),该工具返回来自四个大组织—Apache, Eclipse, Google 以及 Facebook 上数千个开源项目的最相关的代码片段。我们在后端集成了GitHub code search API,用于收集相关的源代码文件,使用抽象语法树(AST)解析和与查询的文本相似性分析,从中提取最相关的方法体。在第二种情况下,RACK根据它们的相关性返回Top-K(例如,K = 10)代码片段,供开发人员进一步分析。还可以通过选中工具提供的复选框来重置整个过程。

(ii)缓解词汇不匹配问题:当非结构化自然语言查询用于代码搜索时,基于文本相似性的搜索技术(例如向量空间模型)通常会遇到这一问题,[3,4]。由于RACK将初始搜索查询转换成来自标准库或开发工具包(即,来自单个词汇表)的相关API类,这样的问题得到了缓解。
(iii)结果显示和见解:RACK不仅将代码搜索结果显示为有意义的排序列表(即,具有相关性见解),还添加了一个内置的源代码查看器,用于结果的详细分析(图1-(e)-(g))。使用查询中匹配的关键字对列表中的每个结果进行注释,这提供了关于其相关性的额外直觉。代码查看器启用了语法高亮显示,这确保了开发人员对代码的方便分析。
(3)性能优化(Performance Optimization): 在查询重构步骤访问关系数据库时,代码搜索步骤涉及GitHub API访问和源代码的重要静态分析。在这两个步骤中,RACK应用Java多线程来优化计算和响应时间。迄今为止,我们的重构任务需要≤10秒,搜索任务平均需要≤2秒,接近实时。
(4)无缝集成和动态语料库(Dynamic Integration and Dynamic Corpus): RACK采用客户机-服务器架构(client-server architecture),其中Eclipse IDE插件是客户机模块,服务器模块(即查询重构引擎)作为网络服务托管。也就是说,任何能够进行HTTP调用的工具都可以使用我们的查询重构服务,这证明了RACK的模块化。另一方面,GitHub API的使用确保了RACK总是从一个自动进化和仔细索引的大型源代码语料库中返回相关代码。
3.2 用例场景
通过用例场景,我们试图解释RACK如何帮助软件开发人员在IDE中完成编程任务。
假设一个开发人员Alice正试图开发一个分析网页的Java应用程序(例如雅虎!财务页面),并提取她感兴趣的某些项目(例如股票价格)。然而,她缺乏必要的经验,因此正在寻找执行相同或相似任务的工作代码示例。她提出了一个查询——“用Java解析html”,并提交给一个网络搜索引擎(例如Google)。搜索引擎会引导她找到一系列编程问答页面和API文档。现在,她需要仔细浏览包含大量文本的页面。虽然这些页面可能有助于提高她在解析方面的知识,但是从这些页面中选择相关的代码示例不仅是一项耗时的工作,也是一项没价值(non-trivial)的工作。她还可能将相同的自然语言查询提交给代码搜索引擎(例如GitHub),但是返回的结果并不乐观。简而言之,她(1)由于内容中的噪音而无法从网络搜索结果中舒适地收集简洁且有效的代码示例,(2)由于其固有的限制——查询和源代码之间的词汇不匹配问题而无法从代码搜索引擎中获得相关结果,(3)发现网络搜索结果或代码搜索结果的显示都无助于搜索后分析(post-search analysis)(即,尝试示例)。
现在,让我们假设Alice已经在自己的IDE中安装了RACK,她遇到了同样的编程挑战。我们的工具从代码注释(例如,图1-(a))中捕获她的自然语言查询,并自动为任务建议相关API类的排序列表以及三个相关性见解(即,KAC、KKC、Relevance)。表1显示了RACK建议的前6个APIs。其中四个类(即67%) Document, Element, Jsoup 以及 Elements是与HTML解析相关的。她可以利用最相关的API类,来重新构建初始查询,并立即尝试由重新构建的查询返回的工作代码示例。现有研究报告称,开发人员经常使用工作代码示例[1]进行实验并从中学习。图2显示了RACK为这个用例返回的前10个相关代码片段,这些代码片段是使用GitHub代码搜索API从数千个开源项目中挖掘出来的。我们的工具不仅提供了每个结果的相关性估计,还用匹配的关键字对它们进行注释,并添加了一个内嵌的源代码查看器。这样的信息和特性可能有助于人们更方便地分析代码结果。
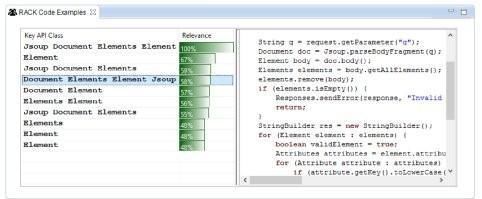
因此,RACK (1)向Alice提供一个或多个简洁且相关的代码示例,而无需花费太多精力或时间(即10-15秒),(2)通过有效的查询重构(即相关的API类)克服传统代码搜索引擎的词汇不匹配问题,以及(3)以有意义的见解和方便的查看面板显示结果。简而言之,我们的工具代替Alice完成了所有繁重的工作,并且为代码搜索和问题解决提供了比传统方法更好的选择。
3.3工作方法
图3显示了我们提出的工具的示意图。本节简要讨论了该工具的内部结构和工作方法,同时我们请读者参阅原始文件[8]了解详细信息。
Keyword-API映射数据库的构建:我们首先通过仔细分析Stack Overflow Q & A中的344K个编程问题和相应的可接受答案(即解决方案)来构建Keyword-API映射数据库(keyword-API mapping database)。使用自然语言预处理(natural language preprocessing)从问题标题中收集关键词,而通过island parsing从答案中提取API类(即,步骤1-3,图3-(a))。然后,我们从每个问答对中捕获关键字(Keyword)和API类之间的内在关联,并构建Keyword -API映射数据库(步骤4-5,图3-(a))。RACK访问该数据库以重构自然语言查询。
查询重构(Query Reformulation): 一旦以非结构化自然语言编写的初始查询被提交到RACK,查询将通过自然语言预处理(natural language preprocessing)(即停止单词移除、标记拆分、词干)进行净化,并转换成关键词向量(a vector of keywords.)。然后,这些关键字被用于收集候选的API类, 从数据库中基于KAC and KKC选出(即,步骤1-3,图3-(b))。接着,这些候选的API被排序,基于它们与关键词(Keyword)的可能性(来自于KAC)以及一致性(来自于KKC)。最后,该工具返回相关API类的排序列表(具有相关性估计),作为初始查询的重构(即,步骤4、5、图3-(b))。
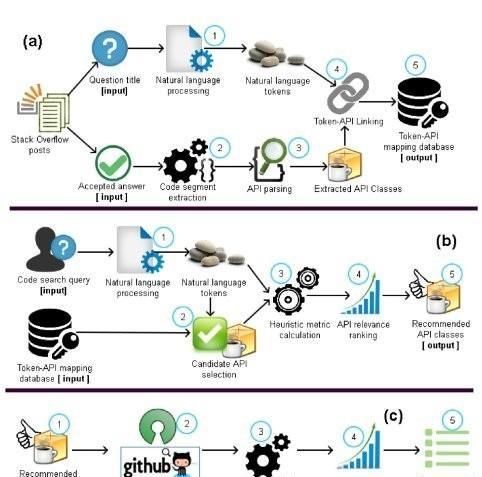
IDE中的代码搜索(Code Search): 一旦包含适当/相关API类的重构查询被提交给RACK,它就使用GitHub search API,并从四大组织——Apache, Eclipse, Google , Facebook——托管的数千个开源项目中收集相关源代码文件。鉴于开发人员通常对尝试执行特定任务的代码片段感兴趣,我们使用基于AST的解析(例如,Javaparser库)(即,图3-(c)中的步骤1-3) 来解析每个源文件中的所有方法。GitHub API为每个结果文件返回一个相关性分数,我们将该分数与从该文件中提取的所有方法的文本相似性分数(与搜索查询)相结合。这种组合为每个代码片段提供了组合相关性(即,方法),并且RACK最终返回IDE中相关代码片段的排序列表(即步骤4、5、图3-(c))。
3.4性能
由于我们最初的论文《[8]》声明是在查询重构的建议中做出了主要贡献,因此RACK的这一部分被进行了严格的评估和验证。为了评估API的建议性能,我们使用从三个编程教程站点——KodeJava、Java2s和JavaB——随机选择的150个代码搜索查询进行实验。评估显示,在Top-10 API建议中,RACK能够为79%的查询提供至少一个相关的API建议,根据文献,这是非常有进步的。与最先进的技术相比较——图恩等人的[9]——不仅验证了我们的性能,也验证了RACK在相关建议中的优越性。鉴于我们的重新构建的查询包含最佳的API类(gold set API classes),并且我们利用GitHub API进行代码搜索,我们的查询也可能返回相关的代码片段,因为GitHub在源代码搜索中应用关键字匹配。
4.本文主要贡献
在本文中,我们提出了一种新的代码搜索工具——RACK,它接受来自开发人员的非结构化自然语言查询(即不需要API信息)作为输入,并从数千个开源项目中返回相关的代码片段作为输出。该工具首先从IDE中的两个工作上下文(例如代码注释)中捕获开发人员的代码搜索意图作为查询,将查询自动转换为相关的API类,然后通过应用它们(指的是转换后的API类)从GitHub search API中收集相关的代码示例。由于Stack Overflow Q & A 站点中的每个问题都总结了一个编程问题/任务,故而相应的答案通常会包含解决该问题的合适的API。因此,我们从Stack Overflow中挖掘成千上万个问题和相应的可接受的答案来建立关键字-API关系(keyword-API associations),从而将自然语言查询(即编程任务)翻译成相关的API类。因此,该工具既可以作为查询推荐器,也可以作为代码搜索引擎。我们将我们的解决方案打包成一个Eclipse插件,允许开发人员在IDE中执行代码搜索,因此,他们可以避免恼人的上下文切换问题。总而言之,我们的工具提供了以下特性来支持开发人员进行代码搜索:
(a) 工具自动将非结构化的自然语言查询翻译成一个编程任务相关的API类。
(b) 确定返回的API类的相关性,基于从成千上万个Stack Overflow上编程问题和回答中挖掘出的关键字-API关系(keyword-API associations)。
(c) 减轻现有技术和传统代码搜索引擎面临的词汇不匹配问题。
(d) 将GitHub search API集成到IDE中,制作成基于IDE的代码搜索,以便结果显示。
(e) 与任何传统搜索不同,为搜索查询和搜索结果提供有意义的相关性见解。
