
 手机网站
手机网站
手机网站
手机网站
< p >几个月前,我们注意到银行集成服务的缓慢部署影响了团队发布代码的能力。工程师至少需要30分钟来构建、部署和监控多个过渡和生产环境中的变更,这消耗了大量宝贵的工程时间随着团队越来越大,我们每天发布越来越多的代码,这变得越来越不可接受。
虽然我们计划实施长期改进,例如将基于亚马逊ECS服务的基础设施迁移到Kubernetes,但为了在短期内提高迭代速度,有必要快速解决这个问题因此,我们决定实践定制的“快速部署”机制
亚马逊电子控制系统部署的高延迟我们的银行集成服务由4000个Node.js流程组成,这些流程运行在由亚马逊的容器编排服务ECS托管和部署的专用Docker容器上在分析了我们的部署流程后,我们将增加的部署延迟归因于三个不同的组件:
组件 开始一项任务会导致延迟除了应用程序启动时间之外,ECS运行状况检查还会导致延迟,这将决定容器何时准备好开始处理流量控制此过程的三个参数是间隔、重试和开始周期。如果健康检查没有仔细调整,容器可能会卡在“开”状态,即使它们已经准备好为流程服务。关闭任务会导致延迟当我们运行ECS服务更新时,一个SIGTERM信号被发送到所有运行的容器为了解决这个问题,在完全关闭服务之前,我们在应用程序代码中使用了一些逻辑来占用现有资源。我们启动任务的速度限制了部署的并行性。尽管我们将最大参数设置为200%,但ECS start-taskAPI调用的硬限制是每次调用只能执行10个任务,并且速度有限。我们需要打400次电话才能把所有的集装箱投入生产。方法探索我们考虑并测试了一些不同的潜在解决方案,以逐步实现
的总体目标 减少生产中运行的容器总数。这当然是可行的,但它涉及到对服务体系结构进行重大更改,以使其能够处理相同的请求吞吐量。在做出这些改变之前,需要进行更多的研究。通过修改运行状况检查参数来调整ECS配置我们试图通过减少间隔和启动周期的值来加强健康检查,但是ECS在启动时错误地将健康容器标记为不健康,导致我们的服务在100%健康状态下从未完全稳定。由于基本问题(慢的ECS部署)仍然存在,这些参数的迭代是一个缓慢而费力的过程。在ECS群集中启动更多实例,以便在部署期间可以同时启动更多任务这将减少部署时间,但不会太多。从长远来看,这是不划算的。通过重新配置初始化和关闭逻辑优化服务重启时间只需稍加修改,我们就可以在每个容器中节省大约5秒钟。尽管这些更改将总体部署时间缩短了几分钟,但我们仍需要将时间延长至少一个数量级,才能认为问题已经解决。这将需要一个完全不同的解决方案
初步解决方案:使用noderequest缓存来“热重载”应用程序代码noderequest缓存是一个JavaScript对象,根据需要缓存模块这意味着多次执行require ('foo ')或从' foo '导入* as foo只会在第一次请求foo模块令人惊讶的是,删除请求缓存中的条目(我们可以使用全局请求来访问它。缓存对象)将强制节点在下次导入模块时从磁盘中重新读取模块。
为了绕过ECS部署过程,我们尝试使用节点的请求缓存在运行时执行应用程序代码的“热重载”一旦收到外部触发(我们将其实现为银行集成服务上的gRPC端点),应用程序将下载新代码来替换现有建筑并清除所需缓存,从而强制重新导入所有相关模块。这样,我们可以消除ECS部署中的大部分延迟,并优化整个部署过程
在Plaiderdays(我们内部的黑客马拉松)期间,来自不同团队的一组工程师聚集在一起,实施端到端的概念验证,我们称之为“快速部署”当我们试图一起构建一个原型时,有一件事似乎出错了:如果下载新构建的节点代码也试图使缓存无效,那么下载程序代码本身将如何重新加载就不清楚了。(解决这个问题的一种方法是使用节点事件发射器,但是它给代码增加了相当大的复杂性。)更重要的是,还存在运行不同步代码版本的风险,这可能会导致意外的应用程序故障
由于我们不愿意在银行整合服务的可靠性上妥协,这种复杂性要求重新考虑“热过载”方法。
最终解决方案:重新加载过程过去,为了在所有服务中运行一系列统一的初始化任务,我们编写了自己的进程包装器,它的名字非常合适,叫做引导加载器。引导加载程序的核心包括设置日志管道、转发信号和读取ECS元数据的逻辑每个服务都是通过将应用程序可执行文件的路径和一系列标志传递给引导加载程序来启动的,这些文件在执行初始化步骤后作为子进程来执行。
在下载预期的部署版本后,我们使用了一个特殊的退出代码来调用process.exit来实现服务更新,而不是清除节点的所需缓存。我们还在引导加载器中实现了定制逻辑,以触发使用此代码退出的任何子进程的进程重载与“热过载”方法类似,这使我们能够绕过ECS部署的成本,快速引导新代码,同时避免“热过载”的陷阱此外,引导加载器层的这种“快速部署”逻辑允许我们将其扩展到运行在格子布上的任何其他服务
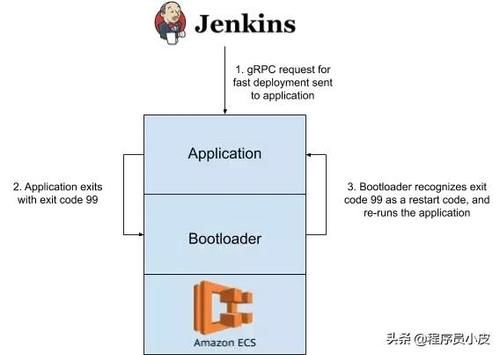
以下是最终解决方案:
Jenkins部署管道向银行集成服务的所有实例发送RPC请求,指示它们“快速部署”特定的提交哈希应用程序接收快速部署的gRPC请求,并根据接收到的提交散列从亚马逊S3下载构建的压缩包。然后,它会替换文件系统上现有的内部版本,并使用引导加载程序识别的特殊退出代码退出引导加载程序使用这个特殊的“重新加载”退出代码看到应用程序退出,然后重新启动应用程序该服务运行新代码下图简要说明了这一过程
结果
我们可以在3周内交付这个“快速部署”项目,并将90%的生产容器的部署时间从30分钟以上减少到1.5分钟
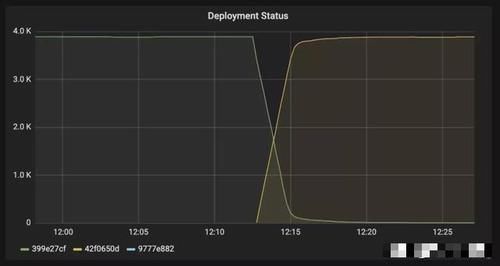
显示了我们为银行集成服务部署的容器数量(提交时用不同的颜色表示)如果你看看黄线,你可以看到它的增长在12:15左右趋于稳定,这意味着我们的集装箱尾部仍在占用资源。
项目极大地提高了格子呢集成的速度,使我们能够更快地发布特性和修复错误,并最大限度地减少在上下文切换和监控仪表板上浪费的工程时间。这也证明了我们的工程文化,即通过黑客马拉松获得的想法来实现具有实质性影响的项目。
最后,我是一名从事开发多年的老JAVA程序员。我辞去了工作,目前正在学习自己的java个人定制课程。今年年初,我花了一个月的时间整理出一个最适合2019年学习的枯燥的java学习产品。我可以把它给每个喜欢java的小伙伴。如果你想得到它,你可以注意我的电话号码,在后台私下信任我:java,你可以免费得到它。
本文转载于微信公众号-InfoQ。如果有侵权,请联系我们。

