
 手机网站
手机网站
手机网站
手机网站
< p >这个问题已经成为老生常谈,并且经常被用作面试的最后话题。网上有很多文章,但是最近我很无聊。然后我记下了自己,感觉比以前更彻底了。
本笔记是我这两天阅读的几十篇文章的总结,所以比较全面。然而,由于我是一个前端作者,我将重点分析由浏览器呈现的页面部分。至于其他部分,我将列出关键词,感兴趣的人可以参考.
注意:本文中的步骤基于一个简单的没有HTTPS的HTTP请求,HTTP2,最简单的DNS,没有代理,服务器没有问题,尽管这是不切实际的
一般过程 网址解析 域名系统查询 TCP连接 处理请求 接受回应 渲染页面 网址分析地址解析:
首先判断您输入的是合法的网址还是要搜索的关键字,并根据您输入的内容执行自动完成和字符编码等操作。
HSTS
由于安全风险,将使用HSTS强制客户使用HTTPS访问页面。你不知道的HSTS
域名系统查询基本步骤

1年。浏览器缓存
浏览器将首先检查它是否在缓存中,否则它将调用系统库函数进行查询。
2年。操作系统缓存
操作系统也有自己的域名缓存,但在此之前,它会向域名服务器发送一个查询请求,以检查域名是否存在于本地主机文件中。
3年。路由器缓存
路由器也有自己的缓存
Ispdns缓存互联网服务提供商域名系统是在客户端计算机上设置的首选域名系统服务器,在大多数情况下,客户端计算机都有缓存
域名服务器查询
如果前面的所有步骤都没有缓存,本地域名服务器将把请求转发到互联网上的根域。下图很好地说明了整个过程:
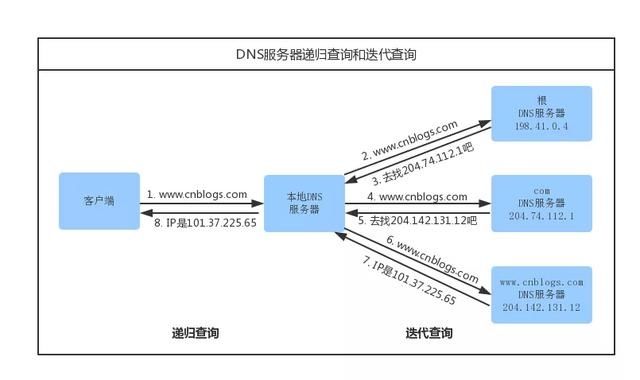
域名服务器(维基百科)
注意事项
递归方法:一路向下,中间不返回,只有在获得最终结果后才返回信息(从浏览器到本地DNS服务器的过程) 迭代方法是本地域名服务器查询根域名服务器的方式什么是域名系统劫持 前端dns预取优化 第三,传输控制协议连接TCP/IP分为四层。发送数据时,每一层都应封装数据:
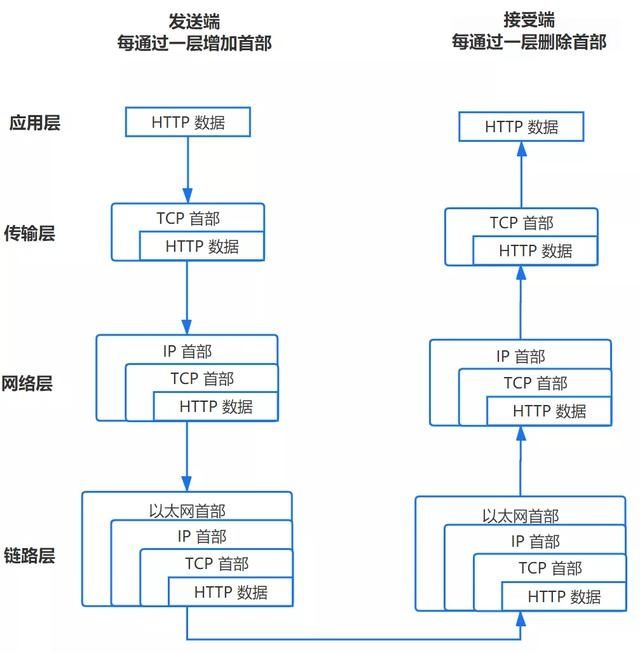
在前面的步骤中,我们已经获得了服务器的IP地址。浏览器将开始构建一个包含
的HTTP消息 请求头:请求方法、目标地址、遵循的协议等。 请求正文(其他参数)注意事项:
浏览器只能发送获取和发布方法,而获取方法用于打开网页 2.传输层:传输协议传输消息传输层将启动到服务器的TCP连接。为了便于传输,数据将被分割(以消息段为单位)并用数字标记,以便服务器在接受消息时能够准确地恢复消息信息。
在建立连接之前执行TCP三次握手
< p >“
”至于TCP/IP三次握手,互联网上有很多笑话和图片生动地描述了这一点。
相关知识点:
SYN洪水攻击
"
3.网络层:IP协议查询Mac地址打包数据段,添加源和目的地的IP地址,并负责查找传输路由
判断目标地址是否与当前地址在同一个网络中,如果是,则根据Mac地址直接发送,否则使用路由表查找下一跳地址,并使用ARP协议查找其Mac地址
< p >“
”注意:在OSI参考模型中,ARP协议位于链路层,但在TCP/IP中,它位于网络层
"
4.链路层:以太网协议以太网协议
根据以太网协议将数据分成“帧”中的数据包,每个帧分为两部分:
报头:数据包的发送者、接收者和数据类型 数据:数据包的具体内容Mac地址
以太网规定所有连接到网络的设备必须有一个“网卡”接口。数据包从一个网卡传输到另一个网卡,网卡的地址就是Mac地址每个Mac地址都是唯一的,并且具有一对一的能力
广播
通过发送数据的方法非常新颖。数据通过ARP协议直接发送到网络中的所有机器。接收方将报头信息与自己的Mac地址进行比较,如果一致,则接受报头信息,否则丢弃报头信息。
注意:收件人响应是单播
服务器接受该请求的验收过程是颠倒上述步骤,见上图。
四、服务器处理请求粗流
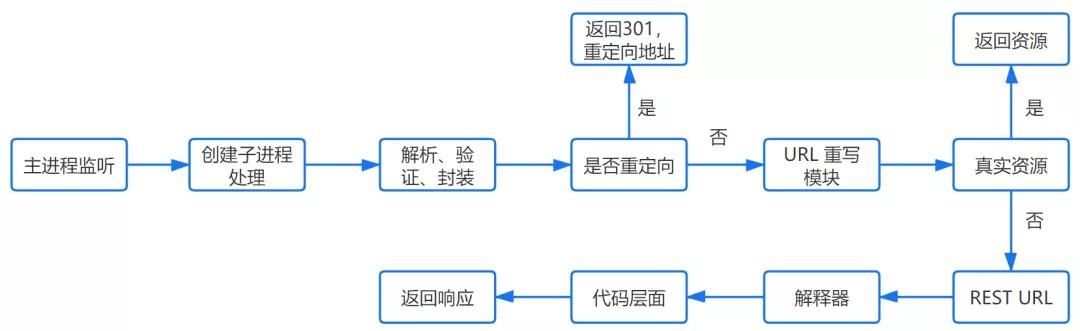
HTTPD
最常见的HTTPD是通常在Linux上使用的Apache和Nginx,以及在Windows上使用的IIS
它监听接收到的请求,然后启动一个子进程来处理该请求
处理请求
接收到传输控制协议消息后,将处理连接,解析HTTP协议(请求方法、域名、路径等。),并执行一些验证:
验证虚拟主机是否已配置 验证虚拟主机是否接受此方法 验证用户是否可以使用此方法(基于IP地址、身份信息等)。)重定向
如果服务器配置了HTTP重定向,它将返回301永久重定向响应,浏览器将根据响应重新发送HTTP请求(重新执行上述过程)
网址重写
将检查网址重写规则。如果请求的文件是真实的,比如图片、html、css、js文件等。,文件将直接返回。
否则,服务器将根据规则将请求重写为REST样式的URL。
然后根据动态语言的脚本决定调用什么类型的动态文件解释器来处理请求
以PHP语言的MVC框架为例。它首先初始化环境的一些参数,根据URL从上到下匹配路由,然后让路由定义的方法处理请求
V.浏览器接受响应 当浏览器从服务器接收到响应资源时,它将分析该资源
首先查看响应头,并根据不同的状态代码做不同的事情(如上面提到的重定向)
如果响应资源被压缩(如gzip),也需要解压缩
然后缓存响应资源
接下来,根据响应资源中的MIME
不同的浏览器内核有不同的渲染过程,但一般过程是相似的。
基本流程
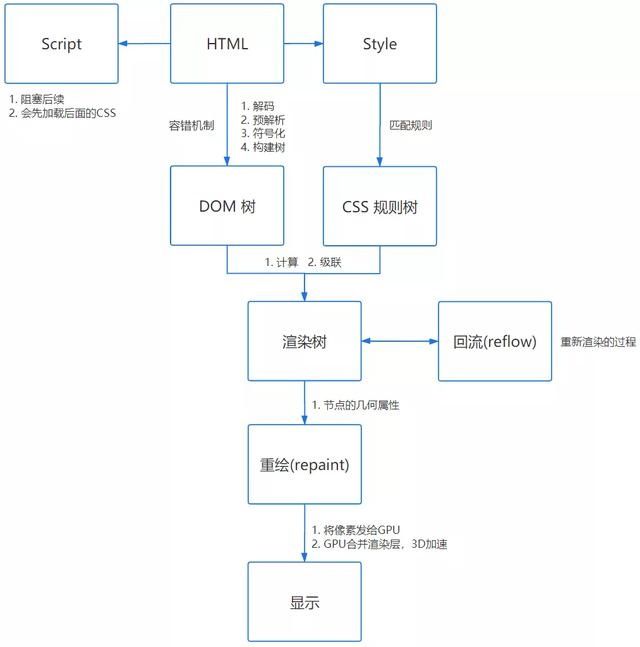
首先需要知道浏览器解析是从上到下逐行完成的。
解析过程可分为四个步骤:
①编码
实际上会传回一些二进制字节数据,浏览器需要根据文件的指定编码(如UTF-8)将其转换成字符串,即HTML代码
②预解析)
预解析的作用是提前加载资源并减少处理时间。它将识别一些将请求资源的属性,例如img标签的src属性,并将该请求添加到请求队列中
③令牌化
的符号化是一个词法分析过程,它将输入解析成符号。HTML符号包括开始标记、结束标记、属性名和属性值
它通过状态机来识别符号的状态,例如,当它遇到状态时就会改变。
④树构造
< p >“
”注意:符号化和树构建并行操作,也就是说,一旦开始标记被解析,就会创建一个DOM节点
"
在最后一个符号化步骤中,解析器获得这些标记,然后用适当的方法创建DOM对象,并将这些符号插入到DOM对象中
网页解析网页解析< p >这是一个示例网页。
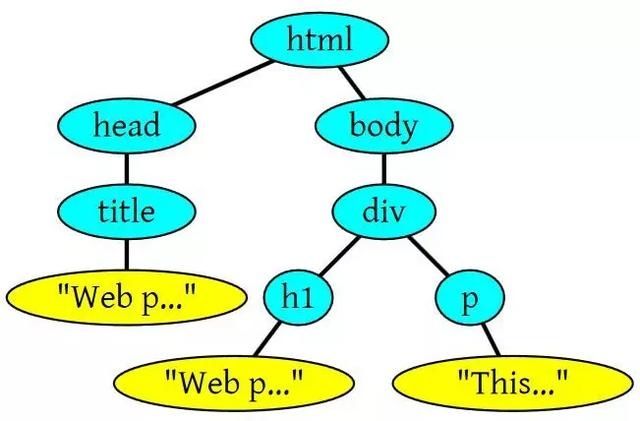
浏览器容错
您从未在浏览器中看到类似的“语法无效”错误,因为浏览器会纠正错误的语法,然后继续工作。
事件
当整个解析过程完成时,浏览器将通过DOMContentLoaded事件通知DOM解析
Css解析一旦浏览器下载了CSS,CSS解析器将根据语法规范处理它遇到的任何CSS
可分为三个阶段:
1.词汇分析 加载JS脚本后,它将首先进入语法分析阶段。它将首先分析代码块的语法是否正确,如果不正确,它将抛出“语法错误”并停止执行。
步骤:
例如,分词将var a = 2分成词汇单位,如var、a、=、和2。解析,将词汇单位转换成抽象语法树代码生成,将抽象语法树转换成机器指令2.预编译JS有三种操作环境:
全球环境 功能环境 evaluate 评价每次进入不同的执行环境时都会创建相应的执行上下文。根据不同的上下文环境,形成函数调用栈。堆栈的底部总是全局执行上下文,堆栈的顶部总是当前执行上下文
创建执行上下文
在创建执行上下文的过程中,主要做了以下三件事:
创建可变对象 参数、函数、变量 建立范围链 验证当前执行环境可以访问变量 确保这指向 3.履行JS线程

虽然JS是单线程的,但实际上有四个线程参与工作:
线程< p >“
”其中三个只是辅助,只有JS引擎线程是
"
JS引擎线程:也称为JS内核,负责解析执行JS脚本程序的主线程,如V8引擎 事件触发线程:属于浏览器内核线程,主要用于控制事件,如鼠标和键盘。当事件被触发时,它会将事件处理程序推入事件队列,并等待JS引擎线程执行。 定时器触发线程:主要控制定时的设置间隔和设置超时。计时完成后,将计时器的处理功能推入事件队列,并等待JS引擎线程HTTP异步请求线程:通过XMLHttpRequest连接后,当通过浏览器中新打开的线程监控readyState的状态变化时,如果设置了状态的回调函数,则将状态的处理函数推入事件队列,等待JS引擎线程执行。注意:同一域名的浏览器的并发连接数是有限的,通常为6
宏任务
分为
同步任务:按顺序执行;只有在前一个任务完成后,后一个任务才能执行 异步任务:不直接执行。只有当触发条件满足时,相关线程才会将异步任务推入任务队列,并等待JS引擎主线程上的任务完成后再执行,如异步Ajax、DOM事件、setTimeout等。