
 手机网站
手机网站
手机网站
手机网站
< p>2019年可以说是“培训前模式”的流行年自BERT开创这一趋势以来,相关方法的研究不仅获得了EMNLP会议最佳论文奖,而且引领了NLP乃至图像领域的发展趋势。
去年,也有很多人工智能游戏超越了人类的水平。人工智能不仅玩了德州扑克、星际争霸和Dota2等复杂游戏,还赢得了《自然》和《科学》等顶级杂志的认可。
199机器的核心在去年一整年里汇编了人工智能、量子计算等领域最热门的七项研究。让我们按照时间顺序来看:年 OpenAI发布具有15亿参数的通用语言模型GPT-2 对的第一次轰动性研究出现在二月。BERT是一个有3亿个参数的语言模型,它刷新了11个自然语言处理任务的记录。在BERT发布后,谷歌OpenAI在2019年2月再次推出了一个更强大的模型,这次这个模型有15亿个参数。这是一个大型的无监督语言模型,可以生成连贯的文本段落,并在许多语言建模基准上取得了SOTA性能。此外,该模型可以实现初步阅读理解、机器翻译、问答和自动摘要,而无需特定任务的训练。
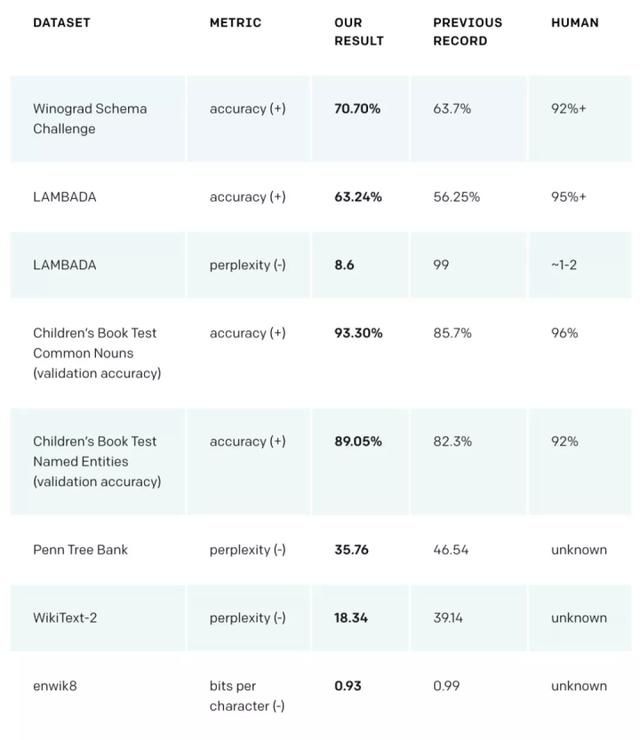
这个型号叫做GPT-2。它是一个基于Transformer的大规模语言模型,包含15亿个参数,在800万个网络数据集上进行训练。训练GPT-2有一个简单的目标:给定文本中所有先前的单词,预测下一个单词GPT-2是GPT模型的直接延伸。它训练了超过10倍的数据量和10倍的参数
GitHub项目地址:https://github.com/openai/gpt-2 论文链接:https://d4mucfpksywv . cloudfront . net/better-language-models/language _ models _ are _ unsupervised _ multimedia _ learners.pdfGPT-2展示了一系列通用而强大的功能,包括生成当前最佳质量的条件合成文本,在该文本中,我们可以将输入输入到模型中,并生成非常长的连贯文本。此外,GPT-2优于在特定领域(例如维基百科、新闻或书籍)训练的其他语言模型,并且不需要这些特定领域的训练数据。GPT-2可以从原始文本中学习诸如知识问答、阅读理解、自动摘要和翻译等任务,而无需针对特定任务的训练数据。尽管这些下游任务远未达到当前的最佳水平,但GPT-2表明,如果有足够的(未标记的)数据和计算能力,各种下游任务可以受益于无监督技术。
最后,基于可能具有巨大社会影响的大规模通用语言模型,并考虑到该模型可能被用于恶意目的,OpenAI在发布GPT-2时采用了以下策略:仅发布GPT-2的较小版本和样本代码,不发布数据集、训练代码和GPT-2模型权重。
ICML 2019年最佳论文:用解耦表示进行无监督学习是不可能的 199强机器学习大会的最佳论文总是会引起人们的广泛讨论在今年6月于美国加州举行的ICML 2019(机器学习国际会议)上,由苏黎世联邦理工学院(ETH)、德国马克斯·普朗克研究所和谷歌大脑联合完成的“挑战分离再呈现的无监督学习中的共同假设”获得了最佳论文之一。在这篇论文中,研究者提出了一个与以前学术预测相反的观点:对于任何数据,都不可能有无监督学习的独立表征(解耦表征)

纸链接:https://arxiv.org/abs/1811.12359
在这篇论文中,研究人员冷静地回顾了这一领域的最新发展,并对一些常见的假设提出了质疑。
首先,研究人员说,理论上,如果没有模型和数据的归纳偏差,无监督学习的解耦表示基本上是不可能的;然后,他们在七个不同的数据集上进行了可重复的大规模实验,并训练了12000多个模型,包括一些主流方法和评价指标。最后,实验结果表明,尽管不同的方法会导致相应的“鼓励”属性的损失,但是在没有监督的情况下,似乎不可能识别完全解耦的模型此外,增加解耦似乎不会降低下游任务学习的样本复杂度。
199研究人员认为,基于这些理论,机器学习实践者没有选择超参数的经验法则,并且在存在大量训练模型的情况下,无监督的模型选择仍然是一个巨大的挑战。 新的神经网络结构搜索方法可以执行各种任务,而无需显式的权重训练 199去年6月,波恩-莱茵-西格尔·应用技术大学和谷歌大脑的研究人员发表了一篇名为“体重不可知的神经网络”的论文,引发了机器学习的循环。在本文中,他们提出了一种神经网络架构搜索方法,这些网络可以执行各种任务而无需显式的权重训练

纸链接:https://arxiv.org/pdf/1906.04358.pdf
在正常情况下,重量被视为训练成直观的特征,如MNIST的角和弧。如果文中的算法能够处理MNIST,那么它们不是特征而是函数序列/组合这可能是对人工智能可解释性的一个打击很容易理解,神经网络体系结构不是“天生平等的”,对于特定的任务,一些网络体系结构比其他模型表现得更好。然而,与体系结构相比,神经网络权重参数有多重要?
德国波恩-莱茵-西格尔-应用技术大学和谷歌大脑的一项新研究提出了一种神经网络架构搜索方法,该方法无需明确的重量训练就能执行各种任务
为了评估这些网络,研究人员使用从均匀随机分布抽样的单个共享权重参数来连接网络层并评估预期性能结果表明,该方法可以找到少量的神经网络结构,无需加权训练就可以执行多个强化学习任务或监督学习任务,如MNIST学习。
CMU培训前模型XLNetBERT的影响尚未平息。谷歌大脑6月份提出的CMU和XLNet在20项任务中超过了伯特的表现,并在18项任务中取得了目前最好的结果。

卡内基梅隆大学和谷歌大脑的研究人员提出了一种新的预训练语言模型XLNet,它在20项任务中全面超过了BERT,如SqL、GLUE和RACE
的作者说,BERT的基于去噪自编码的预训练模型能很好地模拟双向上下文信息,其性能优于基于自回归语言模型的预训练方法。然而,由于需要部分遮罩输入,BERT忽略了遮罩位置之间的相关性,因此预训练和微调效果(预训练-微调辨别)之间存在差异
基于这些优点和缺点,本研究提出了一个广义自回归预训练模型XLNetXLNet可以:1)通过最大化所有可能的因式分解序列的对数似然性来学习双向上下文信息;2)利用自回归本身的特点克服了BERT的缺点另外,XLNet还集成了当前最优的自回归模型Transformer-XL
扩展读数:
20项任务全面滚动BERT,CMU新的XLNet预培训模型Tubang(开源) XLNet团队:只要进行公平的比较,BERT就没有反击的力量。 他们创建的XLNet席卷了全国大学生网络:访CMU杨支林博士 人工智能抓住许多德州扑克夸耀科学2年7月,019年,德·保罗·艾·普勒比在不受限制的德州扑克六人制比赛中成功击败五名人类高手。Pluribus是由脸谱网和卡耐基梅隆大学(CMU)联合开发的,它完成了前任“冷攻击大师”没能完成的任务。这项研究发表在最新一期的《科学》杂志上。
据介绍,由脸书和卡内基梅隆大学设计的比赛分为两种模式:一个人工智能+5人和五个人工智能+1人。Pluribus在两种模式中都获得了胜利如果一个筹码值1美元,Pluribus可以在每场游戏中平均赢得5美元,在与五名人类玩家的比赛中每小时赢得1000美元。职业扑克玩家将这些结果视为决定性的胜利优势。这是人工智能第一次在超过两个玩家(或团队)的大型基准游戏中击败顶级职业玩家
在本文中,Pluribus集成了一种新的在线搜索算法,它可以通过搜索最初的几个步骤来有效地评估其决策,而不是只搜索到游戏结束此外,Pluribus还使用了一种新的更快的自玩不完美信息游戏算法。总而言之,这些改进使得用最小的处理能力和内存来训练Pluribus成为可能。用于培训的云计算资源总价值不到150美元这种效率与其他最近的人工智能里程碑项目形成鲜明对比,在这些项目中,培训通常需要花费数百万美元的计算资源。
Pluribus的自我博弈结果称为蓝图策略。在实际的游戏中,Pluribus使用搜索算法来增强这个蓝图策略然而,Pluribus不会根据对手的趋势调整策略。



去年在人工智能以外的量子计算领域也取得了重要的研究突破。2019年9月,谷歌从美国宇航局网站上提交了一篇名为“量子至尊使用程序式超导处理器”的论文。研究人员首先在实验中证明了量子计算机相对于传统架构计算机的优越性:在世界上第一台超级计算机Summit需要计算1万年的实验中,谷歌的量子计算机只花了3分20秒。因此,谷歌声称实现“量子优势”后来,这篇论文出现在《自然》杂志150周年纪念版的封面上。

这一成就来自科学家们的不懈努力谷歌对量子计算的研究已经过去了13年2006年,谷歌科学家哈特穆特·内文开始探索用量子计算加速机器学习的方法。这项工作促进了谷歌人工智能量子团队的建立。2014年,加州大学圣巴巴拉分校(UCSB)的约翰·马丁尼斯和他的团队加入谷歌,开始制造量子计算机。两年后,塞尔吉奥·博伊索等人发表了他们的论文,谷歌开始专注于实现量子计算优势的任务。
现在,该团队已经建立了世界上第一个量子系统,它超越了传统超级计算机的能力,能够执行特定的计算任务

虽然人工智能没有打败最强的人类玩家塞拉,但它的研究论文仍然是关于自然的2019年10月底,《心灵深处》关于阿尔法星的论文发表在本期《自然》杂志上。这是人工智能算法阿尔法星的最新研究进展。这表明人工智能已经达到了《星际争霸2》中人类对战天空爵士的最高水平,“没有任何游戏限制”,而且它在Battle.net的排名已经超过了99.8%的活跃玩家。

回顾阿尔法星的发展,深度思维在2017年宣布将开始研究阿尔法星,这是一种能够玩实时战略游戏星际争霸2的人工智能。2018年12月10日,AlphaStar击败了Dani Yogatama深度思维最强的玩家。12月12日,阿尔法星以5:0击败职业玩家TLO(TLO是一名虫族玩家,根据游戏评论,其在游戏中的表现约为5000分)。一周后,在12月19日,阿尔法星也以5-0击败了职业玩家MaNa。到目前为止,阿尔法星又向前迈进了一步,达到了主流电子竞技游戏的最高水平。
根据《自然》论文的描述,DeepMind使用一般的机器学习技术(包括神经网络、强化学习的自我游戏、多智能体学习和模仿学习)直接从游戏数据中学习。AlphaStar的游戏风格令人印象深刻——该系统非常擅长评估其战略位置,并且知道何时接近对手以及何时离开。此外,本文的中心思想是将游戏环境中的虚拟自我游戏扩展到一组代理,即“联盟”
联盟概念的核心思想是,仅仅取胜是不够的相反,实验要求主要代理能够击败所有玩家,而“剥削者”代理的主要目的是帮助核心代理暴露问题并变得更强大这并不要求这些代理提高他们的成功率通过使用这样的训练方法,整个代理联盟已经在一个端到端的全自动系统中学习了《星际争霸2》中所有复杂的策略。
2019年,在人工智能的各个领域都有许多技术突破在新的一年里,我们期待着更多的进步。
此外,机器之心于2019年9月底推出了新产品SOTA车型。读者可以根据自己的需要找到机器学习相应领域和任务的SOTA论文。该平台将提供论文、模型、数据集和基准相关信息。
