
 手机网站
手机网站
手机网站
手机网站
做了一个多月的JAVA爬虫爬取百度指数的项目,发现出现了很多问题,总结如下:抓取百度指数的整体思路: 1、首先得模拟登陆百度账号(用selenium+PhantomJS模拟登陆百度,获

小白爬虫第一篇--抓取淘宝文胸数据
1097x768 - 91KB - PNG

python淘宝爬虫基于requests抓取淘宝商品数据
798x446 - 88KB - JPEG
Scrapy爬虫框架:抓取淘宝天猫数据
634x260 - 19KB - JPEG

Scrapy爬虫框架:抓取淘宝天猫数据
678x260 - 40KB - JPEG

Scrapy爬虫框架:抓取淘宝天猫数据
550x260 - 45KB - PNG

Scrapy爬虫框架:抓取淘宝天猫数据
480x260 - 11KB - JPEG

.NET爬虫技术之.NET抓取Web网页数据分析实
709x546 - 89KB - JPEG

爬虫技术可以抓取到淘宝天猫京东订单页的数据
613x428 - 136KB - JPEG

爬虫技术可以抓取到淘宝天猫京东订单页的数据
500x333 - 139KB - JPEG
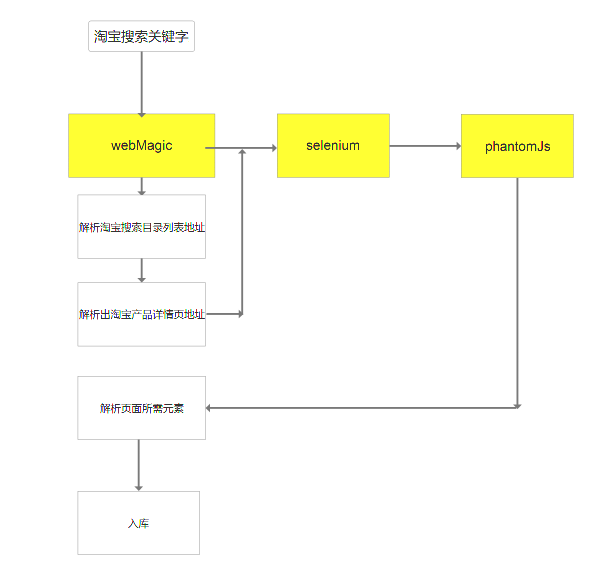
学习用java基于webMagic+selenium+phantomj
600x575 - 22KB - PNG

Python爬虫实战四之抓取淘宝MM照片
860x342 - 61KB - JPEG
[爬虫技术]一个抓取淘宝和天猫平台商品信息的
640x445 - 68KB - JPEG

Python爬虫之一 PySpider 抓取淘宝MM的个人
1164x455 - 43KB - PNG

百度爬虫终于可以抓取淘宝了!内容还是王道!_
300x219 - 19KB - JPEG
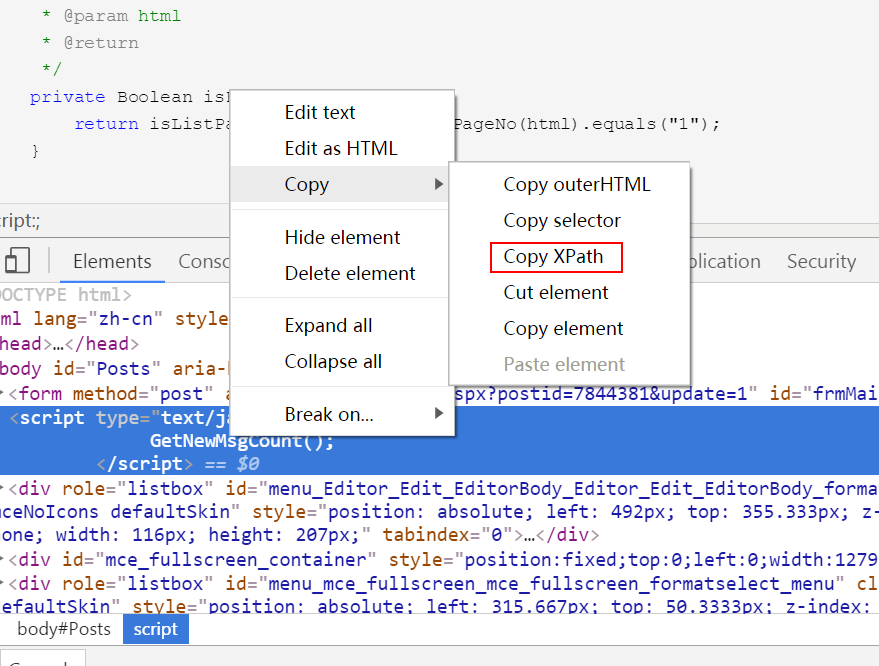
学习用java基于webMagic+selenium+phantomj
879x666 - 133KB - PNG
