
 手机网站
手机网站
手机网站
手机网站
爬虫爬去简书网站上面文章,get不到,求教原因?
922x316 - 54KB - JPEG

Python与简单网络爬虫的编写 - Python开发技术
560x349 - 40KB - JPEG

Python与简单网络爬虫的编写 - Python开发技术
560x349 - 40KB - JPEG

爬虫小说去广告版|爬虫小说(安卓小说阅读器)1
314x436 - 123KB - JPEG
![[Python学习] 简单网络爬虫抓取博客文章及思想](http://www.2cto.com/uploadfile/Collfiles/20141005/20141005085305128.jpg)
[Python学习] 简单网络爬虫抓取博客文章及思想
717x377 - 61KB - JPEG

我分享了@爬虫医师 的文章 来自执业兽医师陈
440x331 - 28KB - JPEG
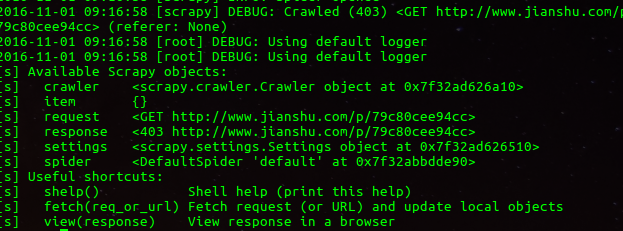
爬虫爬去简书网站上面文章,get不到,求教原因?
623x231 - 88KB - JPEG

Scrapy轻松定制网络爬虫 - Python开发技术文章
550x388 - 34KB - PNG

Python scrapy 实现网页爬虫 - Python开发技术
721x305 - 36KB - PNG

python与简单网络爬虫的编写 - python开发技术
700x522 - 57KB - JPEG

Python与简单网络爬虫的编写 - Python开发技术
700x373 - 46KB - JPEG
微博 文章 - 爬虫类特殊解剖构造
900x600 - 248KB - JPEG
微博 文章 - 爬虫类特殊解剖构造
900x600 - 218KB - JPEG

Python3 爬虫实例(三) -- 爬取豆瓣首页图片 - Py
1045x803 - 115KB - PNG

Python 爬虫网页抓图保存 - Python开发技术文章
788x588 - 152KB - PNG
编者按:互联网上有浩瀚的数据资源,要想抓取这些数据就离不开爬虫。鉴于网上免费开源的爬虫框架多如牛毛,
什么语言都还是次要的,我想知道爬虫都有什么样的功能,我迄今了解到的功能就是爬去某网站的文章,但不清楚
如何预防网络爬虫?看这篇文章就够了-WeTest腾讯质量开放平台(wetest.qq.com),是由腾讯游戏官方推出的一
在前几次学习中,我学会了获取一篇文章并实现字段解析。现在是要通过第一个url开始爬取所有的文章。如何
很明显可以看出,这是来自于“爬虫王国“苹果公司的新品发布去 App 商店搜 好奇心日报,每天看点不一样的。
爬虫开始运行时需要一个初始url,然后会根据爬取到的html文章,解析里面的链接,然后继续爬取,这就像一棵
智能Web广告爬虫系统研究,智能家居系统的研究,智能系统研究室,智能系统与控制研究所,智能结构系统研究所,
该文章还宣布了在 12 月 11 日上线的视频广告投放价格。(图片来自:微信广告助手) 这就代表着日后我们
本文来自《好奇心日报》,更多好文章请在各大应用商店搜索“好奇心日报”。这是来自于“爬虫王国“苹果公司
