
 手机网站
手机网站
手机网站
手机网站
(1) shuffle join:是hive中的普通的join方式,基于map/reduce实现,join的key通过shuffle汇集到相应的reduce里做join。这种join方式不考虑数据量和数据模型设计,比较耗费资源,是较

Hive中Join的原理和机制
808x1533 - 92KB - PNG

【大数据微课回顾】杨卓荦:Hive原理及查询优
1280x588 - 75KB - JPEG
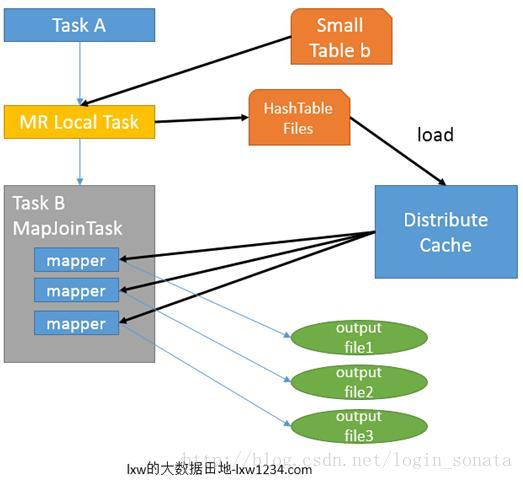
一,Hive中join的原理和机制
523x480 - 26KB - JPEG

Hive mapreduce SQL实现原理--SQL最终分解为
948x431 - 63KB - PNG

大数据学习14:Hive中Join的原理和机制
628x541 - 27KB - JPEG

Hive中原理及使用MAP JOIN
667x538 - 192KB - PNG
![[一起学Hive]之十-Hive中Join的原理和机制-中国](http://newsimg.tuxi.com.cn/7xipth.com1.z0.glb.clouddn.com/0625-3.jpg)
[一起学Hive]之十-Hive中Join的原理和机制-中国
712x647 - 164KB - JPEG

Hive体系结构(二)Hive的执行原理、与关系型数
727x380 - 25KB - JPEG

实时分析系统以及hbase、hive和impala的区别
561x284 - 105KB - PNG
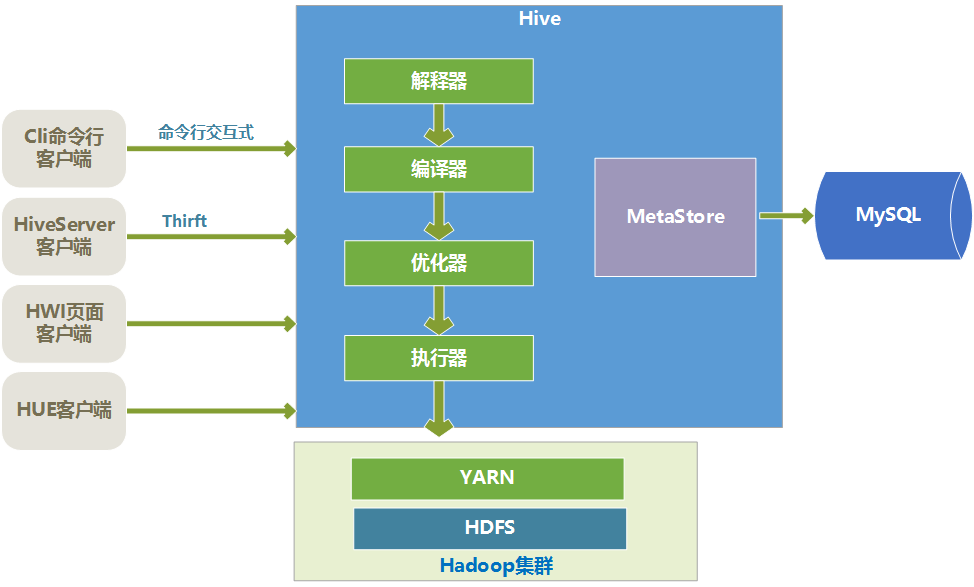
几种 hive join 类型简介
974x587 - 25KB - PNG

【大数据微课回顾】杨卓荦:Hive原理及查询优
1280x752 - 47KB - JPEG

【大数据微课回顾】杨卓荦:Hive原理及查询优
1280x993 - 56KB - JPEG

08-Hive高级查询join - 谢华东的博客 - CSDN博
952x636 - 246KB - PNG

【大数据微课回顾】杨卓荦:Hive原理及查询优
1280x774 - 100KB - JPEG

【大数据微课回顾】杨卓荦:Hive原理及查询优
1280x626 - 49KB - JPEG
