
 手机网站
手机网站
手机网站
手机网站
SELECT COUNT(*) FROM (SELECT DISTINCT id FROM TABLE_NAME WHERE … ) t; 在实际运行时,我们发现Hive还对这两阶段的作业做了额外的优化。它将第二个MapRe

Hive SQL优化之 Count Distinct
550x208 - 8KB - JPEG
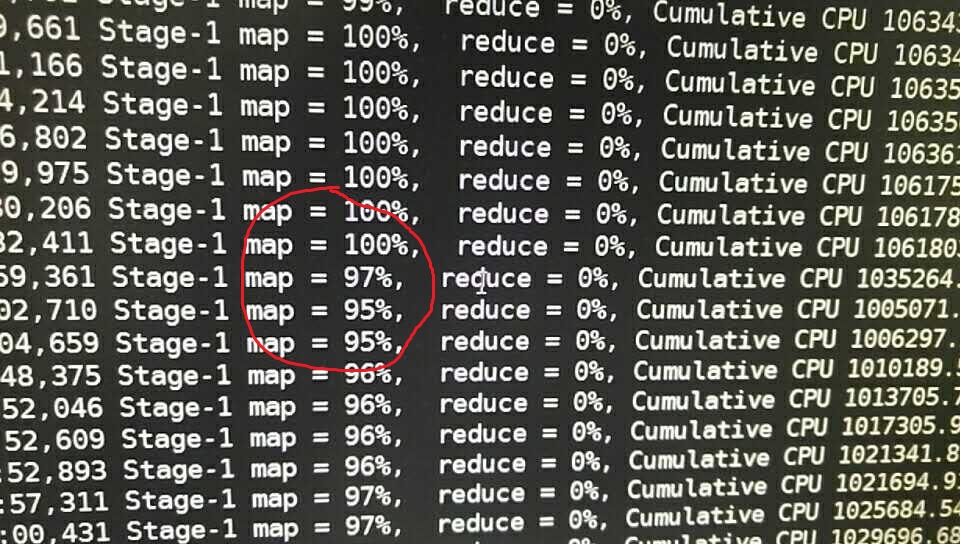
Hive SQL count(distinct)效率问题及优化 - 零、
960x544 - 199KB - JPEG

Hive SQL count(distinct)效率问题及优化_数据库
960x544 - 108KB - JPEG

Hive性能优化总结.docx
993x1404 - 91KB - PNG

【大数据微课回顾】杨卓荦:Hive原理及查询优化
1280x489 - 35KB - JPEG
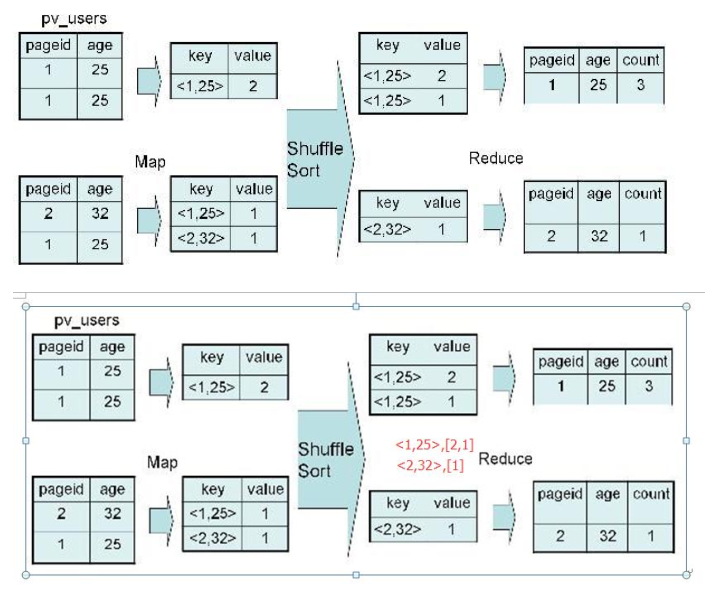
Hive(六)hive执行过程实例分析与hive优化策略
720x593 - 290KB - PNG

【大数据微课回顾】杨卓荦:Hive原理及查询优化
1280x564 - 58KB - JPEG

hive数据倾斜优化策略
554x254 - 82KB - PNG
![[Hive]-执行计划解析以及常规优化](https://images2018.cnblogs.com/blog/1409212/201806/1409212-20180626153202310-601917468.png)
[Hive]-执行计划解析以及常规优化
907x420 - 60KB - PNG

hivesql优化
280x220 - 5KB - JPEG

Hive – Distinct 的实现
633x229 - 16KB - JPEG

Hive – Distinct解析
633x229 - 16KB - JPEG

Hive – Distinct 的实现
347x467 - 18KB - PNG

Hive – Distinct 的实现
600x217 - 14KB - JPEG

oracle竟然不能count(distinct a,b) 模仿oracle 的
459x242 - 19KB - PNG
