
 手机网站
手机网站
手机网站
手机网站
题主刚学爬虫,准备爬一下八重樱图片。我把百度图片搜索的崩坏三八重樱的网页源码爬下来后,用findall函数找出所有以.jpg结尾的网址,可是返回列表中出了些奇怪的东西——列

python--BeautifulSoup库函数find_all()
644x422 - 11KB - PNG
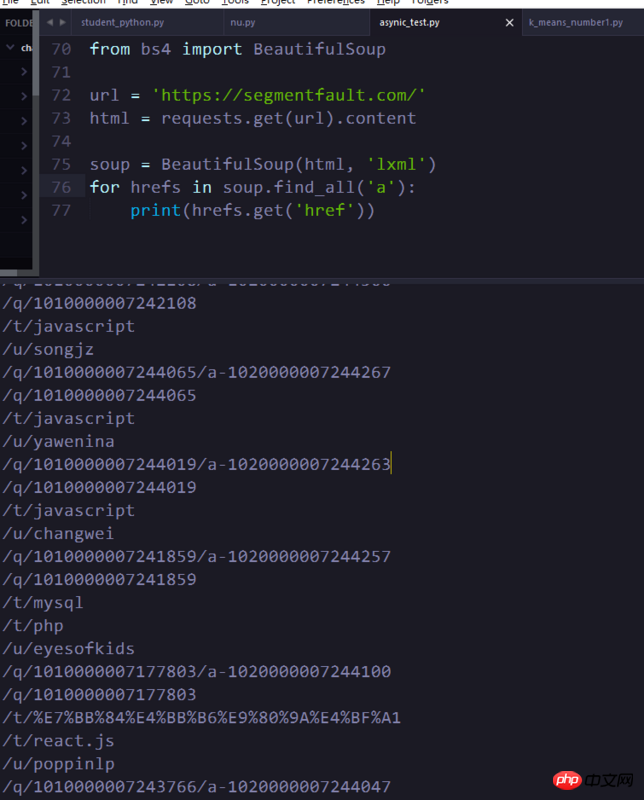
python - 使用BeautifulSoup的find和find_all函数
644x800 - 212KB - PNG

Python 正则表达式的使用(re findall finditer mat
530x280 - 23KB - JPEG

Python 正则表达式的使用(re findall finditer mat
432x247 - 21KB - JPEG

python之正则表达式 | match | split | findall | sub替
475x420 - 25KB - PNG

python2.7爬虫糗事百科程序的正则表达式怎么
897x384 - 175KB - JPEG
![[python爬虫] BeautifulSoup爬取+CSV存储贵州](http://img.blog.csdn.net/20171030161631699)
[python爬虫] BeautifulSoup爬取+CSV存储贵州
849x417 - 189KB - JPEG
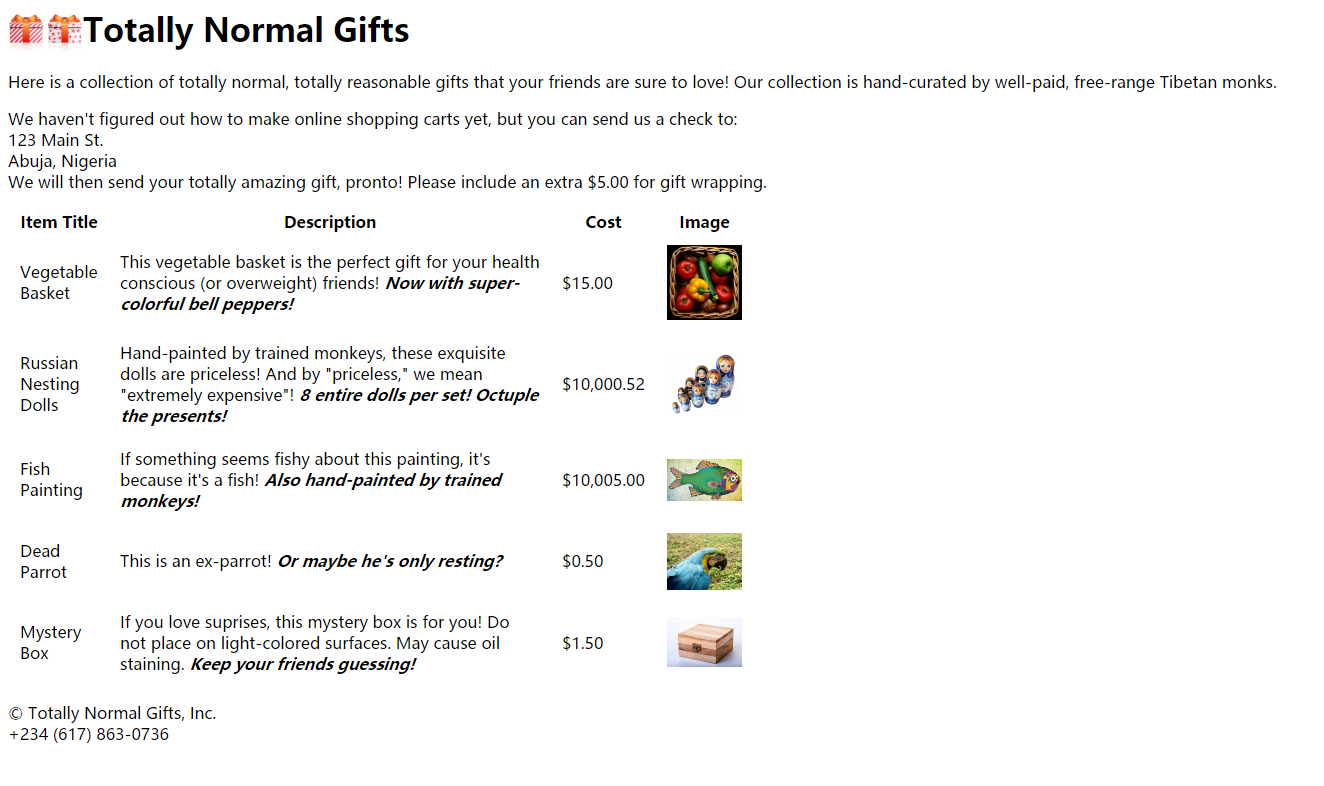
python爬虫(二)--第一个爬虫程序 - 猴子的新衣
1324x786 - 208KB - PNG
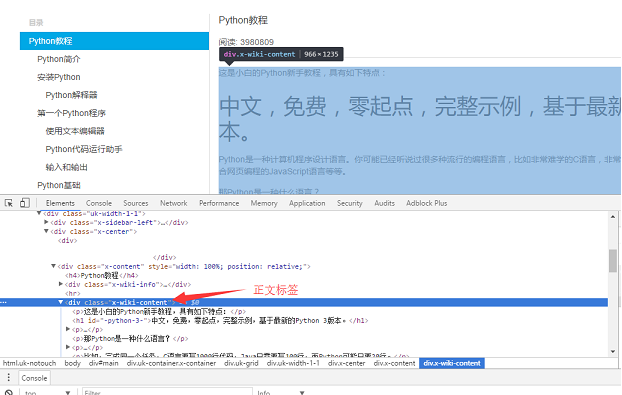
Python爬虫实战:将网页转换为pdf电子书 - 临泽
622x395 - 101KB - PNG
Python第十节-爬虫前正则模块学习_科技_49八
347x216 - 9KB - JPEG

python2.7入门---正则表达式
550x403 - 112KB - PNG
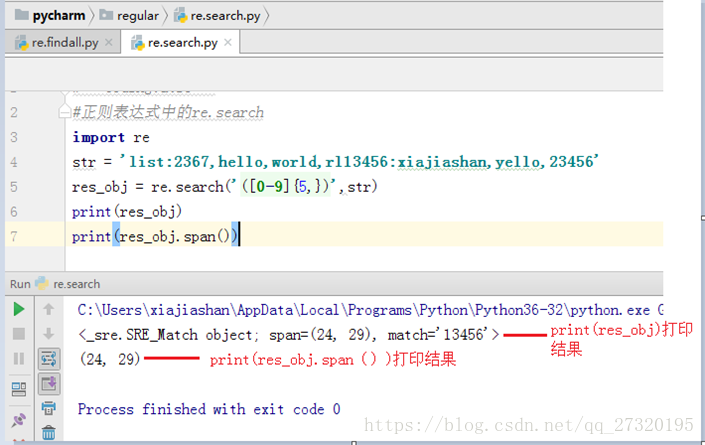
Python高级
705x445 - 117KB - PNG
【Python3.6】:廖雪峰python教程转换成 PDF
1866x865 - 358KB - PNG

python爬豆瓣高分电影榜
703x473 - 18KB - PNG

【MOOC】Python网络爬虫与信息提取-北京理
797x378 - 145KB - PNG
