
 手机网站
手机网站
手机网站
手机网站
 大数据流计算之三S演义:Storm、Spark、
大数据流计算之三S演义:Storm、Spark、
620x338 - 55KB - PNG
 远古流媒体发布服务器●流媒体视频云计算
远古流媒体发布服务器●流媒体视频云计算
556x448 - 31KB - JPEG
 薄壁堰流计算
薄壁堰流计算
1060x439 - 24KB - JPEG
 计算流照片-正版商用图片04p1b3-摄图新视界
计算流照片-正版商用图片04p1b3-摄图新视界
700x525 - 185KB - JPEG
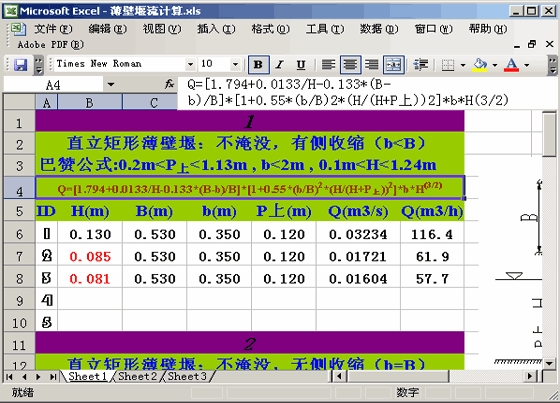 薄壁堰流计算
薄壁堰流计算
560x403 - 158KB - JPEG
 一文读懂大数据计算框架与平台
一文读懂大数据计算框架与平台
575x338 - 135KB - PNG
 计算流
计算流
1024x768 - 298KB - JPEG
 计算信息流
计算信息流
1024x768 - 250KB - JPEG
 计算流
计算流
1024x768 - 347KB - JPEG
 计算流
计算流
1024x768 - 333KB - JPEG
 计算信息流
计算信息流
1024x768 - 149KB - JPEG
 计算流
计算流
1024x768 - 372KB - JPEG
 计算信息流
计算信息流
1024x768 - 201KB - JPEG
 计算信息流
计算信息流
1024x768 - 235KB - JPEG
 码流计算
码流计算
704x295 - 32KB - JPEG
流计算秉承一个基本理念,即数据的价值随着时间的流逝而降低,如用户点击流。因此,当事件出现时就应该立即进行处理,而不是缓存起来进行批量处理。为了及时处理流数据,就
流计算概述什么是流数据:数据有静态数据和流数据。静态数据:很多企业为了支持决策分析而构建的数据仓库系统,其中存放的大量历史数据就是静态数据。技术人员可以利用数
[最佳答案] 不同于批量计算模型,流式计算更加强调计算数据流和低时延,流式计算数据处理模型如下:使用实时数据集成工具,将数据实时变化传输到流式数据存储(即消息队列,如DataHub);此时数据的传输变成实时化,将长时间累积大量的数据平摊到每个时间点不停地小批量实时传输,因此数据集成的时延得以保证。此时数据将源源不断写入流数据存储,不需要预先加载的过程。同时流计算对于流式数据不提供存储服务,数据是持续流动,在计算完成后就立刻丢弃。数据计算环节在流式和批量处理模型差距更大,由于数据集成从累积变为实时,不同于批量计算等待数据集成全部就绪后才启动计算作业,流式计算作业是一种常驻计算服务,一旦启动将一直处于等待事件触发的状态,一旦有小批量数据进入流式数据存储,流计算立刻计算并迅速得到结果。同时,阿里云流计算还使用了增量计算模型,将大批量数据分批进行增量计算,进一步减少单次运算规模并有效降低整体运算时延。从用户角度,对于流式作业,必须预先定义计算逻辑,并提交到流式计算系统中。在整个运行期间,流计算作业逻辑不可更改!用户通过停止当前作业运行后再次提交作业,此时之前已经计算完成的数据是无法重新再次计算。不同于批量计
什么是流计算:在当下这个数据容量呈几何倍暴增的时代背景下,数据的价值在其产生之后,将随着时间的流逝,逐渐降低。因此,我们最好在事件发生之
介绍流计算系统的基本概念。流计算应用需求静态数据很多企业为了支持决策分析而构建的数据仓库系统,其中存放的大量历史数据就是静态数据。技术人员可以利用数据挖掘
