
 手机网站
手机网站
手机网站
手机网站
近年来,刑法和网络安全法逐渐增加了保护个人隐私信息的条款同时,我国即将颁布《个人信息保护法》,进一步完善个人隐私和数据安全的保护细节隐私安全计算也有相关的行业标准:国家标准和通用标准特别是通用标准有专门针对隐私安全的相关标准“基于安全多方计算的数据流通和产品技术要求和测试方法(T/BDC 001-2019)”。
1992年1月10日,020,首席技术官蔡朝超应邀作为大数据领域前沿技术的代表出席2019年中国大数据技术与应用年会。蔡朝超认为,随着国家和个人越来越重视数据保护和隐私安全,隐私计算作为一种更新的数据流通和协作方法,可以帮助企业按照国家在相关法律法规最初颁布和完善时认可的合规方法进行数据流通和协作。另外,在项目登陆方面,一些常见场景已经登陆,可以投入实际生产和应用。首先,不同的公司和企业将收集不同种类的数据(如网上购物数据、健康和安全数据、社会数据等)。)根据他们的业务需要。同一个人不同维度的数据分别由不同的公司收集和存储,形成数据维度的分离另一个是样本的碎片化。例如,北京的医院主要有北京及其周边地区用户的健康数据,而上海的医院有上海及其周边地区用户的健康数据,从而形成区域或样本的自然分离
这些数据的分离将导致数据挖掘和人工智能建设过程中的一些困难,例如缺少样本或相关特征函数,这阻碍了人工智能的发展数据的流通可以弥补这一块的不足,而数据的流通与合作可以使人工智能发挥更好的作用。
但是随着对数据安全和个人隐私的日益重视,相关法律法规的颁布和出台也给数据流通与合作带来了一些挑战。传统方法暴露出一些缺点,如不能有效保护个人隐私,不能完全保护核心数据不被泄露。这些促使了新的数据流和协作方法的出现,例如隐私计算。
隐私计算为最初无法合并的数据提供了机会。它使我们能够拼接更多的数据来挖掘更新的信息,从而促进整个社会的智能发展。因此,隐私计算将逐渐成为人工智能的基础设施
隐私计算是一门跨学科的学科。这是一个数据科学和工程、密码学、分布式计算和存储的综合项目,而不是单一的密码学它涉及多种技术,包括差异隐私、多方计算多学科中心、联邦学习、远程教育等
在当今的技术环境中,隐私计算最大的技术挑战是项目的登陆:如何使隐私计算高效并能够登陆是现在最大的挑战隐私计算贯穿于数据流通的整个过程,自然与数据和计算相关。设计师对数据和场景的理解也非常重要。只有当他在数据科学和工程实践方面有丰富的经验时,他才能设计出真正工程可用的产品。
我们刚刚引入了各种隐私计算方法,那么它如何真正保护数据并帮助企业进行跨领域的数据挖掘呢?
多方安全计算是基于同态加密、秘密共享、混淆电路、模糊传输等技术的综合技术
的显著优点是每一次加密都是随机的,因此加密后数据不能存储或重用,从而防止数据被离线攻击。此外,多方安全计算需要多方协作参与。使用前,完全确定谁将参与计算。任何缺少或过多的参与者都将导致计算失败。
同时,还能有效保证原始数据不会被送出仓库,送出的数据可以控制:“谁、什么时候、什么操作”可以提前设置,充分保证了数据的可控性和安全相关要求。
使用一个简单的例子来展示隐私计算是如何实际实现的:秘密共享
有三个政党,甲乙丙,每个政党都有自己的秘密:一个数字,他们都不希望自己的数字被别人知道,但是他们都想做一些事先指定的事情,比如寻找三个政党的数字之和。传统的方法是直接对数字求和。这是最简单的方法,但它不能保护隐私。
使用秘密共享方法:首先,将a的原始数据随机分成三个数字,并将这三个数字相加,得到a、b和c来做类似的事情。分裂后,甲保留一个数字甲(0),然后给乙(1)和甲(2)给丙,乙和丙也这样做,给对方一个随机数。由于甲总是手里拿着一个数字,乙和丙不能根据甲给出的两个随机数甲(1)和甲(2)推断出甲的真值
经过这一步,每边都得到了三个数字,他们可以分别找到这三个数字的总和,但是通过这三个数字不能颠倒原始值同时,他们也可以根据原来设定的要求计算出A+B+C。只要把这三个数字加起来,就可以得到原始数字的总和。通过这个过程,我向您展示了如何通过隐私计算的方法来计算我们想要的数据,但是我不需要公开我的原始数据。

,当然,这是一个附加约定的例子。这种方法可以实现减法和乘法,除法也可以通过加法、减法和乘法的近似运算得到。通过这一理论,我们可以制作一个基于类SQL的统计分析工具来实现传统的数据挖掘分析方法,但也可以保护隐私和原始数据
除了使用秘密共享来保护数据之外,我们还需要通过建模来实现数据挖掘。这种技术通常被称为联合学习
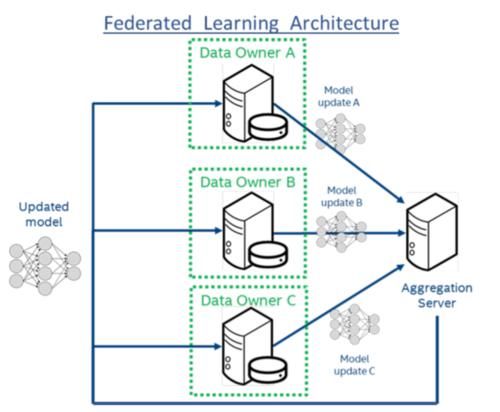
照片来源:https://www . Intel . ai/ai/WP-content/uploads/sites/69/multi-institutional-dl-modeling-wo-sharing-patient-data . pdf
联邦学习(Federal Learning)是谷歌在2016年首次提出来解决安卓手机终端用户在本地更新模型分析,不想将用户本地手机的数据上传到谷歌的问题。它可以保证用户自己的数据始终站在用户一边,但实现了联合建模的过程。
它有几个适用的场景:样本量不足,希望有更多的样本量一起建模;建模时,特征不足,需要更多的尺寸特征。联邦学习也可以用来实现联合建模。
在整个过程中,所有原始数据都可以保存在数据用户中,而不需要离开仓库。在此过程中,仅传输模型梯度,传输过程将被加密。因此,有双重保护,既保护原始数据,也保护梯度传输。因为原始数据的信息内容和汇总梯度仍然非常不同,所以整个数据传输成本也将大大降低。
删除单个特征,同时保留统计特征以保护用户隐私
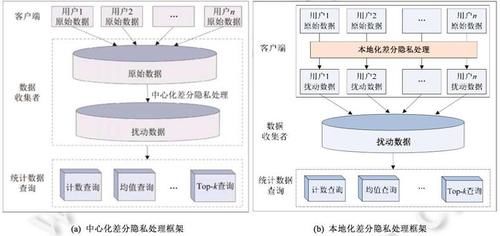
照片来源:http://www.jos.org.cn/jos/ch/reader/create_pdf.aspx?文件编号= 5364 & journal id = jos
差异隐私可通过扰动机制将适当的噪声注入原始数据,从而有效防止差异密码分析。例如,剩余数据的总和可以通过首先计算1000个数据的总和,然后计算990个数据的总和来推断这个过程很难通过增加噪声来实现。差分隐私中添加的噪声被设置为规则分布,在计算统计值(如计算平均值)时,信息的噪声将相互抵消,最终可以有效地获得相关的统计特征。
现在在行业中有许多不同隐私的成功应用:苹果使用不同隐私从苹果手机收集行为统计数据,以改进和优化产品设计;谷歌使用差异隐私来收集和分析用户网站访问信息,同时保护用户隐私。
差异隐私可细分为中心差异和局部差异。中心差异意味着数据在一个地方收集和处理。另一个是本地评分,也就是说,数据在从手机发送出去之前经过了不同的处理。本地评分现在更受欢迎,因为用户可以完全有效地保护和控制他们的数据。
以上三种方法主要基于算法和软件来保护数据。现在有另一种技术来保护硬件和环境中的数据,称为可信执行环境。
可信执行环境的原则是中央处理器上的一个安全区域,它为数据和代码执行提供了一个更安全的空间。这个区域不容易被恶意软件和其他非法用户攻击。在该安全区域进行安全相关计算,以确保其保密性和完整性。
在这项技术中也有许多模式和标准,如ARM的信任区(TrustZone)、英特尔的SGX等。然而,它高度依赖硬件,完全依赖芯片,共享中央处理器计算能力和外围资源因此,它也将受到许多硬件资源的限制,包括它是否真正信任硬件资源。
综上所述,隐私计算可以帮助企业按照现阶段国家认可的合规方法实现数据流通和协作。在项目登陆方面,一些常见场景已经完成,可以投入实际生产和应用。隐私计算将帮助跨数据挖掘走向下一个里程碑,成为人工智能建设的基础设施。
介绍的分享者:蔡朝超,数字技术首席技术官,以前是脸书技术主管。他领导并参与了身份匹配、数据质量验证、广告用户肖像和视频推荐系统等的研发。在机器学习算法开发和数据科学方面有丰富的实践经验
