
 手机网站
手机网站
手机网站
手机网站
雷锋网&第三次人工智能挖掘,作为会议的主要合作媒体,参与了国际清洁发展机制的报告
8月24日上午,复旦大学宋志坚数字化医学与智能诊疗分院发表了题为“计算机辅助诊疗深度学习:问题、机遇与挑战”的演讲
宋志坚教授是复旦大学杰出教授、数字医学研究中心主任、上海医学影像计算与计算机辅助干预重点实验室主任。
在演讲中,宋教授分享了该团队在前列腺磁共振成像(Multiparameter共振)诊断、临床数据增强和头颈放射治疗危险部位分割方面的成就。
以mpMRI诊断为例,由于数据量和特异性的问题,判断前列腺癌是否具有临床显著风险是一个很大的临床需求。宋教授的团队建立了专门用于前列腺癌诊断的网络架构,连续八个月在前列腺大挑战(ProstateX Grand Challenge)中排名第一。
此外,宋教授还对人工智能在医学领域的前景表达了自己的看法:“从经济角度来看,自第三次工业革命以来,创造财富的新技术力量并没有真正到来。每个人都期待第四次工业革命给人们带来新的机遇和发展动力。”“
包含了对人工智能的希望。深度学习是人工智能的核心技术之一然而,在深度学习(特别是在医学应用中)方面仍然存在四个问题:个人舆论宣传偏离科学本身、监管政策、黑盒问题、隐私和黑客攻击以及数据的数量和质量低于
是宋志坚教授的演讲。雷锋网编辑
宋志坚而不改变原意:我是外科导航和外科机器人领域的研究员。近年来,人工智能,尤其是深度学习,得到了广泛的应用。我们还在这一领域开展了一些研究工作。今天,我们想与大家分享结合我们实验室的具体工作,深入学习医学诊断和治疗带来的机遇和问题。众所周知,让计算机为我们工作和帮助我们解决问题大致有两种方式。
是人工建模的第一个想法。这一思想的步骤是先提出问题,然后对问题进行深入的分析和讨论,在此基础上提出算法,然后根据算法进行编程。

的另一个想法是机器学习方法,也是人工建模,最典型的是神经网络,但只有一半的模型是人工构建的,而剩下的一半模型,如神经网络参数,不是人工确定的,而是通过训练数据获得的,即根据我们想要输出的结果和实际结果之间的差异,最终通过重复迭代来确定网络参数。

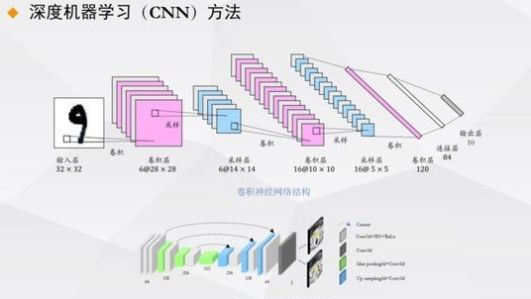
如果网络有许多隐藏层,一般称为深度学习网络。深度学习近年来发展迅速,可以解决许多非线性问题。
过去,我们常常依靠手工建模来解决问题。现在我们有可能通过深入学习取得巨大进步。换句话说,深入学习给我们带来了许多机会。牛津大学
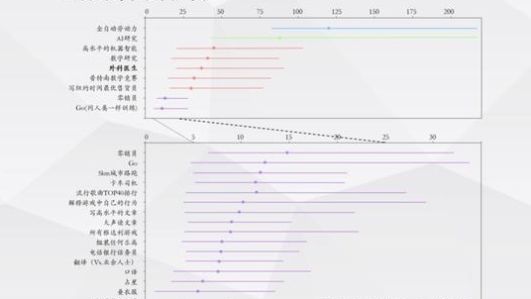
的研究人员对未来几年哪些工作可能被人工智能取代进行了评估。其中,与我们医务人员最相关的外科医生很可能在2016年后的大约35年内被人工智能取代(文章没有具体说明取代的程度)
近年来,有许多关于医学诊断和治疗中的深入学习的研究。我们可以快速回顾这个领域的进展。首先,让我们来看看人工智能在肺结节诊断中的相关实验。人工智能超过了18名放射科医生中的17名。肺炎和心肌肥厚的AUC指数分别为0.63和0.87。三维CT诊断在卒中研究中的AUC达到0.73
,深入学习的诊断速度非常快,是手工作业的150倍。
此外,还有利用深入学习进行基因组学研究的案例。
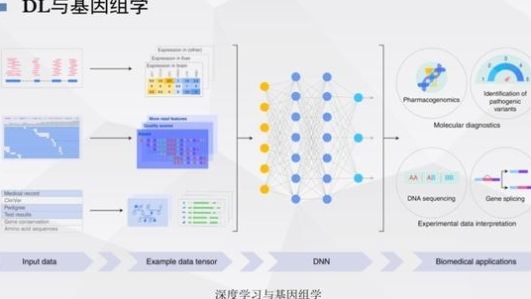
对皮肤癌和黑色素瘤的诊断准确率分别为0.96和0.94。这一领域的研究非常广泛,进展迅速。以上是基因组学的典型网络结构,由于时间关系,将不再描述。
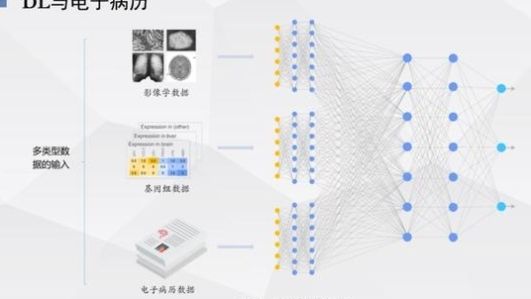
是电子病历。它以影像学、基因组学和电子病历为输入和训练对象。所建立的网络可用于疾病的自动诊断。人们对某件事的理解通常来自科学实验或临床实践。鉴于深入学习在疾病诊断和治疗领域的应用,我们实验室开展了一些工作。我借此机会简要介绍我们的工作,并具体介绍三个例子。
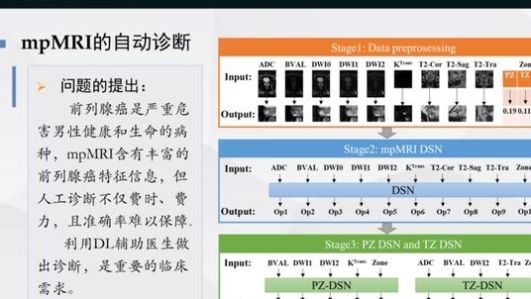
是第一个引入前列腺癌诊断的。判断前列腺癌是否具有临床显著风险是一个非常大的临床需求。
我们使用多参数磁共振数据,因为图像体积很大,所以医生的诊断工作量很大;另一个重要原因是医生通过磁共振成像对前列腺癌的诊断不同于通过计算机断层扫描对肺部和肝脏疾病的诊断。前列腺癌的特异性不是很好,诊断也比较困难。因此,通过多参数磁共振图像诊断前列腺癌是每个人都在研究的前沿课题。
我们的总体思路如下:
首先,我们对前列腺癌进行粗略定位,即预处理其次,我们建立了一个专门的前列腺癌诊断网络。在此基础上,我们对其进行培训和测试,以了解其准确性,这是总体框架。
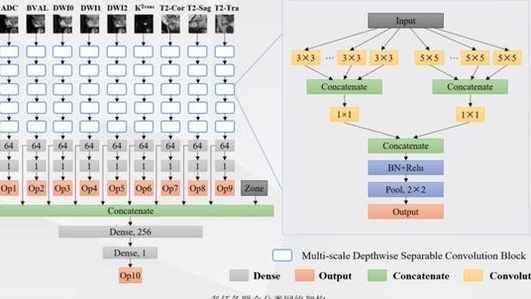
具体而言,我们对每个参数的前列腺数据进行连续卷积处理让我们看看每个小广场。放大后,它看起来像这样。我们首先卷积某个图像,比如256*256图像,乘以3*3*64,然后形成256 * 256 * 64卷积。
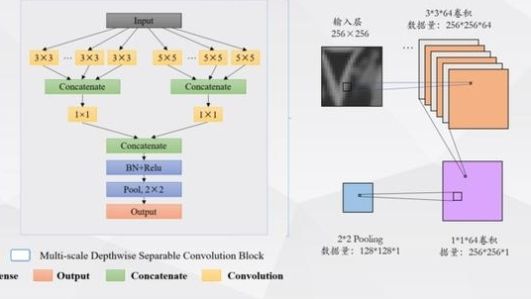
卷积完成后,我们将执行另一个1*1*64的卷积运算。这将256*256*64转换为256*256*1,即3*3的卷积,然后是5*5的卷积最后,我们连接两个卷积并执行另一个池操作。然后在2*2汇集之后,256*256变成128*128回顾
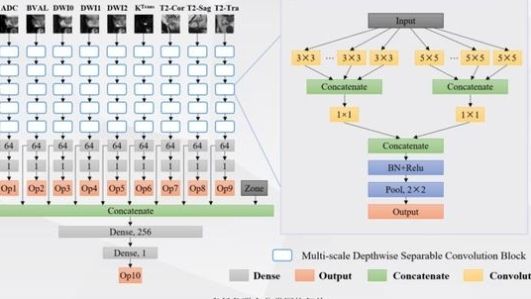
,假设是256*256图像,然后是128*128*64,这是一个8*8的图像。我们将8×8图像的每个像素和每个参数的卷积与前列腺癌的位置相结合,将其连接成完整的连接进行判断,最终得到一个结果。
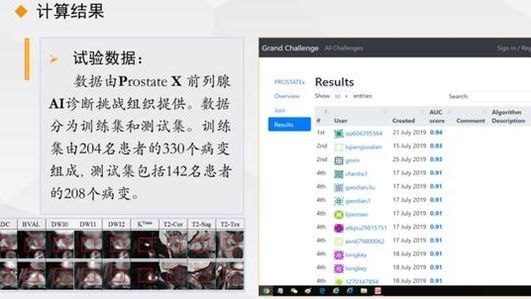
我们使用的数据集是SPIE提供的前列腺挑战数据集。训练集包括204名患者的330个病灶,测试集包括142名患者的208个病灶。
现在经过测试,我们的结果连续八个月排名第一。
我认为,最重要的是建立一个专门的前列腺癌诊断网络架构。我们做的第二项工作是临床数据增强
在前列腺穿刺导航研究中,必须首先对前列腺进行分割将会有一个问题,即很难获得包括前列腺数据在内的临床数据此外,医生在这方面的工作量很大。
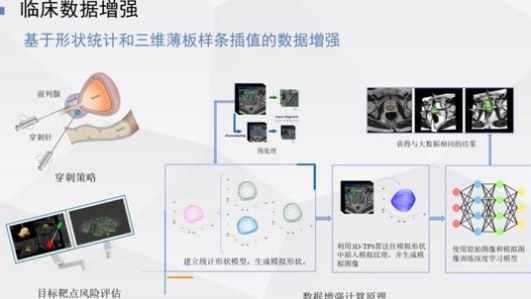
所以我们做了一个图像增强工作,即如何从小数据形成大数据
的基本思想如下:首先对图像进行预处理在此基础上,我们使用统计模型来增强每个训练集图像的数据。也就是说,从概率统计的角度来看,前列腺轮廓的最大概率是什么形状?
,因此,可以根据一组轮廓生成多个新轮廓,然后可以针对某个生成的轮廓找到对应于最接近轮廓的图像,然后可以通过使用对应于轮廓的最接近关系来插值对应图像的纹理。因此,大数据是由小数据生成的基本想法是这样的,然后原始数据和我们生成的数据被训练以得到结果。
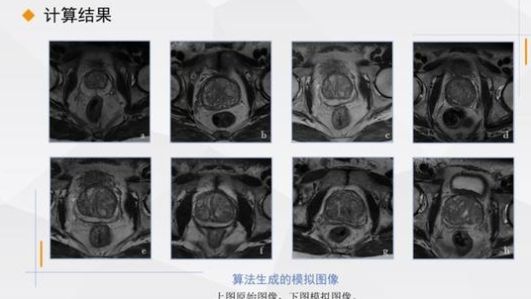
这是由小数据生成大数据的图形结果
正如我们看到的,上面是提供的原始数据,下面是我们的模拟如你所见,我们生成的图像非常漂亮,就像真实的一样,所以有用吗?
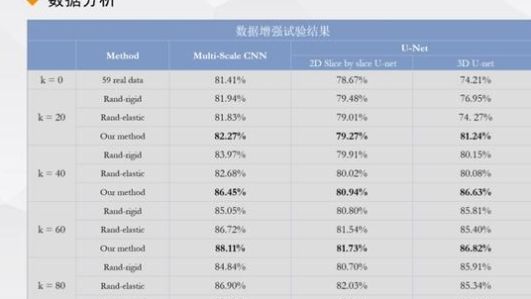
我们做了实验,并用美国有线电视新闻网和联合国电视台进行了验证可以看出,随着生成数据的增加,图像分割精度也在快速提高。因此,我们生成的数据在网络培训中很有用。当数据不足时,我们可以使用数据增强方法来部分解决这个问题。
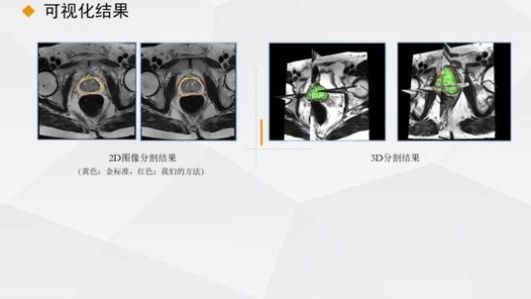
这是我们的数据增强实验,以图像分割为例来验证增强后的数据。上图是分别在2D和3D上的前列腺分割结果。
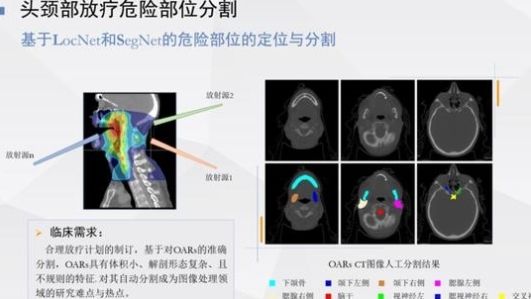
第三项工作是头颈部放射治疗,它危及器官分割
头颈部放射治疗通常避免一些危险器官,即这些危险器官在放射治疗过程中不会受损通常有9到10个濒危器官,需要人工描绘。医生的工作量很大。有可能使用人工智能自动分割濒危器官吗?
我们工作的基本思路是:首先,因为训练集中的图像已经被分割,所以我们提取分割后的图像而不需要其他图像,从而形成两个系列的图像由于训练速度快,我们对这两个系列的图像进行了降采样。
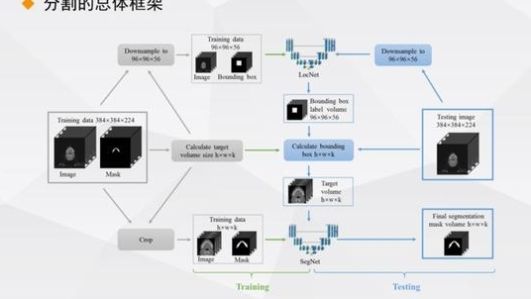
对于该图像,我们使用传统的计算方法用小立方体来框定分割的位置。
首先,训练找到头部和颈部器官的大致位置,将此图像输入名为LocNet(基本结构类似Unet)的第一个网络,并对其进行训练。
训练是基于我们所关心的器官的位置,看看我们所训练的和它有什么不同?如果存在差异,则迭代以确定该参数。
的最终结果是定位整个器官的位置,然后根据这个位置找到相应图像的位置,然后只对我们在这个图像中确定的与器官相关的位置进行第二次训练,称为SegNet,并通过它进行训练分割。当
测试数据时,当确定两个网络结构时,首先定位数据,然后根据位置对数据进行分段
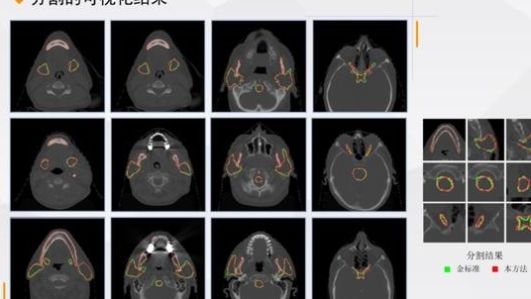
这是我们分割的具体可视化结果
可以看出,九个位置的分割相对准确当然,也有不准确的地方。我们的一些测试数据不太准确。
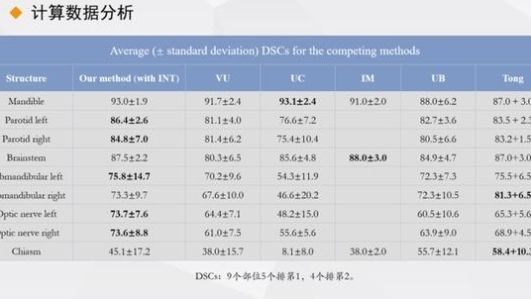
从总体平均数据比较中,我们使用了两个参数
一是骰子系数与其他国际方法相比,九个职位中有五个排名第一,两个排名第二。第二,95%的HDs距离,在九个位置中有七个排名第一,两个排名第二。可以看出,我们的工作相当成功。最后,
是我们的一些想法和对未来机会的简要介绍。我们可以回顾工业革命的历史第一次工业革命以蒸汽机为标志,蒸汽机与医学没有什么关系,至少不是直接关系。第二次工业革命的标志是电的发明,它应该与医学间接相关。以计算机和信息技术为标志的第三次工业革命与医学有着更密切的关系。例如,计算机断层扫描、核磁共振、正电子发射断层扫描等。都有利于计算机技术。换句话说,信息技术促进了医学的发展,特别是诊断和治疗的进步。现在,第四次工业革命还没有到来(有人说它就要来了),第三次工业革命的红利已经基本耗尽。这是什么意思?
意味着还没有形成新的增长点,财富的增长正在逐渐萎缩。一些国际利益集团,尤其是旧发达国家的利益集团,不得不抢走别人的蛋糕来维持原有的生活水平。因此,我们可以看到世界上一些奇怪的现象。例如,你不能生产电视机,但是我可以,所以我已经获得了很多财富。将来,你可以生产,但是我的质量比你的高,而且我仍然可以盈利。然而,如果这项技术不突破很长一段时间,稍后再回来,原有电视制造商的利润将会迅速下降。在第四次工业革命的浪潮中,谁带头,谁就有更大的发展空间。因此,这些年对于国家间的竞争非常重要。
目前,新的增长点可能集中在以下几个方面:一是人工智能,其核心应该是深度学习,此外还有受控核聚变、石墨烯、量子信息、新能源等其中,深度学习与医学关系最为密切。然而,如果要在这方面取得突破,仍有许多问题需要解决。

1。公众舆论偏离了科学我们在公众舆论中所宣传的和我们实际做的有一些不同首先,我们应该认识到深度学习和传统方法的最大区别在于它不完全依赖于人工建模,而是在很大程度上依赖于大数据训练来形成参数和确定模型因此,在过去,许多人工建模不能解决或不能解决坏问题。通过深入学习,我们可以增加新的机会。但与此同时,我们也应该看到,深度学习也有其自身的一些问题。例如,如果传统的建模方法推理非常严格,那么将输入100个数据,100个数据将是准确的。然而,人工智能的方法对于100个数据中的一些可能不准确,但是在临床上,100个数据不允许有问题。
2、监管政策
监管政策法规将限制临床应用的深入学习例如,国际工程师协会将自动驾驶分为五个级别,第五个级别是完全自动驾驶,无需人工干预。然而,实际政策仅限于四级,也就是说,它不能完全自主驾驶,至少人们应该在附近观看。如果将
应用到人工智能的临床层面,每个人一般都应该是3级。也就是说,不可能把疾病诊断的所有重要问题都交给人工智能,至少在很长一段时间内是这样。
3、黑盒问题
欧洲通用数据保护条例规定,如果人工智能要用于医学,特别是临床,必须解释已建立的网络的基本原理,这正是人工智能和深入学习的弱点。

4,隐私和黑客攻击,如何防止数据被黑客攻击

5,数据的数量和质量
如果我们在临床上获取数据并对其进行错误的标记,这些都是在医学特别是临床上应用深度学习需要解决的问题。
就是一个典型的例子。这是今年4月发表在美国妇产科杂志上的一篇文章。采用两种模型来判断和推测白蛋白水平与宫颈癌预后的关系。从

深入研究中获得的结果不同于从临床共识和我们的传统模型中获得的结果。
人工智能认为,这种蛋白的水平与宫颈癌的预后没有直接关系。所以,按照传统的想法,这应该是一个重要的发现。但是为了让每个人都接受这项研究的结果,有必要解释原因人工智能是如何得出这个结果的所以本文在讨论部分说:我们研究的遗憾是深入学习不能解释为什么会出现这种结果。我们只能说训练有素的网络测试就是这样一个结果。要接受这个结果,我们需要深入学习,并有更深的解释。雷锋网
