
 手机网站
手机网站
手机网站
手机网站
\r

今年6月在上海举行的KubeCon2019上,华为云作为开源领域的积极贡献者和推动者,为高性能计算开启了云本土批处理计算平台——火山,帮助企业的计算能力像火山一样爆发。本项目基于华为云容器平台大规模高性能计算应用管理的最佳实践。在原有K8s的基础上,组成了作业调度、设备管理等多个短板。
目前,火山已经在华为云上连接了一站式人工智能开发平台ModelArts、云容器实例CCI和云容器引擎CCE等多种服务,是整个高性能计算领域不可或缺的基础。在斯坦福大学今年5月发布的最新DAWNBench名单中,华为云模型艺术公司(Huawei Cloud ModelArts)以2分43秒的时间在图像识别训练中获得了世界第一名,这离不开火山的帮助。
同时,得益于火山高性能的任务处理机制,华为云基因容器服务(Huawei Cloud Gene Container Service)将基因测序效率提高了30%,成为基因测序行业中的一匹黑马,受到许多国内领先基因测序公司的青睐。自开源以来,华为的云火山项目吸引了腾讯、百度、快速通道和AWS的贡献者。
背景:
随着集装箱化和集装箱布局技术的普及,越来越多的上层企业开始拥抱K8s生态。然而,不可否认的是,本地K8s对人工智能和大数据操作场景的支持并不高。如果最终用户希望将现有业务迁移到K8s平台,他们可能会面临以下问题:
1。群组调度): S2/]大数据/人工智能作业通常包含多个任务,而业务逻辑通常要求Pod同时启动或不同时启动。例如,如果Tensorflow作业只是具有单一角色的Ps或Worker,则无法正常执行。
2。公平共享(Fair-Share):K8s集群中将部署多个命名空间,每个命名空间可以提交多个作业。如何调度资源以避免命名空间中资源的无限压缩,以及如何确保作业之间的公平资源调度?
3。GPU拓扑感知(GPU Topology Awareness):S2/]一项常见的人工智能训练/推理工作,为了达到更高的性能,经常需要使用多个GPU一起完成。此时,GPU的拓扑结构和设备之间的传输性能将对计算性能产生很大影响。目前,K8s提供的扩展资源调度机制不能满足调度过程中的拓扑感知问题。
4。集群配置): S2/]许多上层工具要求用户在服务开始前配置工具的集群状态,以便于系统中节点的互通和识别。例如,MPI(消息传递接口)作业要求用户使用命令行参数“--host”配置集群的所有节点信息,并且还依赖于节点之间的SSH互通。因此,用户还应该考虑如何自动配置和管理服务集群。
5。此外,如何监控整个作业集群的状态?如何处理单个吊舱故障?如何解决任务依赖问题?这些都是需要解决的问题。
基于此,华为云火山(huawei cloud Volcano)在解决此类问题的基础上,致力于为BigDATA/人工智能场景提供一个通用、稳定、可扩展、高性能的本地批处理计算平台,方便以Kubeflow、KubeGene、Spark为代表的上层业务组件的集成和使用。
概述:

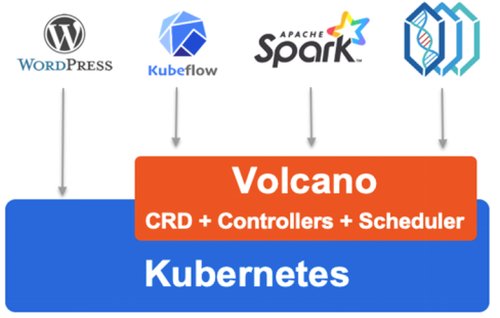
图2:火山商业全景
如图2所示,华为云火山抽象出K8s上批量计算的公共基础层,弥补了K8s向下调度能力的不足,向上提供了灵活、公共的作业抽象。目前,该项目最重要的两个组成部分分别是火山调度器和火山控制器。

图3:kube-batch介绍
1.火山调度器:这个组件从库比批处理开始,库比批处理是一个从社区调度SIG的子项目。这是一个可扩展的增强调度程序。其主要支持能力是:
行动:
(1)①分配:正常的资源分配。
②先占:先占。当系统中有高优先级作业并且系统资源不能满足请求时,将触发资源抢占操作。
(3)回收:资源回收。库伯批处理将使用队列按比例分配资源。在系统中添加或删除队列时,回收将负责恢复资源并将其重新分配给剩余的队列。
插件:
(1) ①DRF,或称显性资源公平,旨在确保在各种类型资源共存的情况下,尽可能满足分配公平原则。其理论来源于加州大学伯克利分校的论文“显性资源公平:多种资源类型的公平分配”。
(2)一致性:资源的一致性,以确保系统关键资源不会被强制回收。
③分组:对资源进行分组,以确保在操作中分组的Pod资源不会被强制驱逐。
在库比批处理的基础上,火山调度器(Volcano-Scheduler)进一步引入了更多领域特定的动作和插件,包括binpack、gpushare、gputopiaware等。
2.火山控制员:火山提供了一个通用和灵活的抽象工作,大众工作(批处理)。火山爆发,穿过CRD。控制器负责与调度器合作并管理作业的整个生命周期。主要功能包括:
①自定义作业资源(Custom Job Resources):与K8s中内置的作业(Job)资源相比,火山作业有更多增强的配置,如任务配置、提交重试、最小调度资源数、作业优先级、资源队列等。
(2)作业生命周期管理(Job life Management):火山控制器将监控作业的创建,创建和管理相应的子资源(Pod、ConfigMap、Service),刷新作业进度摘要,并提供命令行界面以方便用户查看和管理作业资源。
(3)任务执行策略:多个任务通常在一个作业下关联,任务之间可能存在相互依赖关系。火山控制器支持任务策略的配置,这有助于在异常情况下重试或终止任务间关联。
④扩展插件:在作业提交和Pod创建的多个阶段,控制器支持配置插件执行定制的环境准备和清理,如常见的MPI作业。提交前需要配置SSH插件,以完成Pod资源的SSH信息配置。
让我们以MPI作业的YAML片段为例,向您展示作业控制器作为一个整体的功能(为了便于理解,在与扩展功能相关的字段中添加了注释)。

图volcanjob示例(/examples/integrations/MPI/MPI-examples . YAML)
通过以上介绍,当回头看图5来整理华为云火山的普通操作的执行过程时,很容易理解。
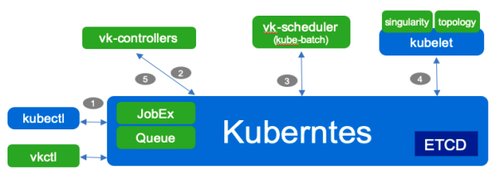
图5:火山组件和调度流程
1.用户通过kubectl创建volcanjobresources。
2.火山控制器监控作业资源的创建,验证资源的有效性,根据作业规范创建相关Pod、服务、配置映射和其他资源,并执行配置的插件。
3.火山调度程序监控Pod资源的创建,并根据策略完成Pod资源的调度和绑定。
4.库布雷负责创建Pod资源,业务开始执行。
5.火山控制器负责作业的后续生命周期管理(状态监控、事件响应、资源清理等)。)。
调度效率:
除了易用性和可扩展性之外,在大数据/人工智能场景中,资源调度的效率(成功率)通常可以有效减少业务运行时间,提高底层硬件设备的利用率,从而降低使用成本。我们比较了联合调度场景下TF作业和本机调度程序的执行时间:
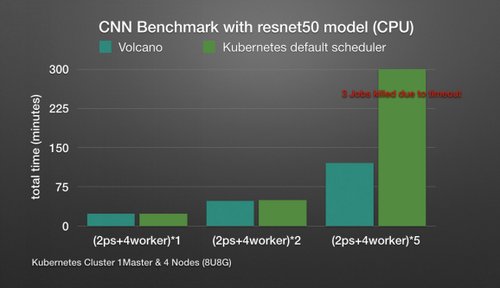
图6:火山和默认调度程序之间作业执行时间的比较
参照图6,发现在单个作业的执行环境中,两种执行模式之间的运行时间没有明显差异。但是,当集群中有多个作业时,由于本机调度程序不能保证调度的分组,极端的情况将直接发生:作业之间会有资源竞争,相互等待,上层服务直到超时才会正常运行。这时,调度效率会大大降低。
社区和贡献:
目前,华为的云火山项目仍在发展壮大。更多功能也处于设计和开发阶段。如果您感兴趣,请随时加入我们的Slack讨论,提问,给出意见和贡献代码。此外,从9月18日至20日,华为的全面互联互通会议将在上海举行,届时将有多个与云相关的技术论坛。华为和其他本土技术大师和传道者也将访问该网站,与开发者进行面对面的交流和互动,并期待与您会面。
请指出重印的来源。
