
 手机网站
手机网站
手机网站
手机网站

想了好几天没想出来的 并列排序复杂度问题?
448x336 - 154KB - PNG

快速排序的空间复杂度\/快速排序的适用场景\/快
578x410 - 35KB - JPEG

ZD第三十讲(归并排序及外排序)PPT_word文档
1080x810 - 75KB - JPEG

hadoop 辅助排序 - 蓝讯
280x220 - 7KB - PNG

各种内部排序性能比较数据结构课程设计.doc
993x1404 - 53KB - PNG

比较排序算法及复杂度分析 - C\/C++ - 次元立方
546x293 - 12KB - PNG

快速排序基于 - 蓝讯
280x220 - 16KB - PNG

基础:多任务处理(13)--Fork\/Join框架(解决排序问
543x332 - 13KB - PNG
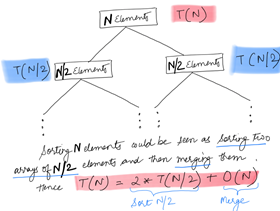
能是最可爱的一文读懂系列:皮卡丘の复杂度分
280x211 - 37KB - PNG

java有序数组合并 - 蓝讯
280x220 - 7KB - PNG

浅谈算法和数据结构: 四 快速排序(2)_Java123
517x528 - 80KB - PNG

浅谈算法和数据结构(4):快速排序-其它-@大数
517x528 - 40KB - JPEG

《dive into python》的笔记-第十讲:分治法
438x308 - 14KB - JPEG

宣文霞《算法设计与分析》第2章 递归与分治策
1152x864 - 63KB - PNG

排序|LOFTER
360x175 - 7KB - PNG
MERGE算法进行比较次数,最大为总长度 - 1。此时两个子数组的元素轮流加入暂存数组B,因此共比较n - 1次。 结果:C(n) = nlogn - n + 1 综合1和2得,合并排序算法时间复杂度为
的归并排序法;因为传统的归并排序所消耗的空间主要是在归并函数(把两个有序的函数合并成一个有序的函数),所以如果要让时间复杂度为 O(1) ,那么也只能在归并函数中做文章
O(nlogn)和O(nlog2n)是一样的。。归并排序如果不借助辅助空间的话,复杂度为O(n^2),借助的话就是O(nlogn)(O(nlog2n))
故复杂度是 O(nlogn) 因为题目要求复杂度为O(nlogn),故可以考虑归并排序的思想。 归并 2)写出merge函数,即如何合并链表。 (见merge-two-sorted-lists一题解析) 3)写出merges
//指向合并后数字的结尾 int i2 = length-1; //指向合并前a1的结尾 int i1 = length1-1; //指向 排序算法之归并排序及其时间复杂度和空间复杂度 在排序算法中快速排序的效率是非常
其时间复杂度为O(nlogn),归并排序的比较是分层次来归并的(第一次是两两归并,之后再在第一次归并的基础上两两归并,每一层归并的次数为上一层除二,最终形成一二叉树,该二
首先你说归并排序最坏的情形为O(NlogN),这是不正确的归并排序如果不借助辅助空间的话,复杂度为O(n^2),借助的话就是O(nlogn)(O(nlog2n))归并排序 平均复杂度是 O(nlogn) 比较快 快速排序快速排序的最坏情况基于每次划分对主元的选择。基本的快速排序选取第一个元素作为主元。这样在数组已经有序的情况下,每次划分将得到最坏的结果。一种比较常见的优化方法是随机化算法,即随机选取一个元素作为主元。这种情况下虽然最坏情况仍然是O(n^2),但最坏情况不再依赖于输入数据,而是由于随机函数取值不佳。实际上,随机化快速排序得到理论最坏情况的可能性仅为1/(2^n)。所以随机化快速排序可以对于绝大多数输入数据达到O(nlogn)的期望时间复杂度。一位前辈做出了一个精辟的总结:"随机化快速排序可以满足一个人一辈子的人品需求。" 随机化快速排序的唯一缺点在于,一旦输入数据中有很多的相同数据,随机化的效果将直接减弱。对于极限情况,即对于n个相同的数排序,随机化快速排序的时间复杂度将毫无疑问的降低到O(n^2)。解决方法是用一种方法进行扫描,使没有交换的情况下主元保留在原位置。 综合来说快速排序速度最快,时间复杂度最小。希望对你有所帮助!
归并排序每次会把当前的序列一分为二,然后两部分各自排好序之后再合并,这样的话你可以手动模拟出一颗二叉树来,每一层的总计算量是O(n)的,总的层数是O(logn)的,所以总的复杂度是nlogn
合并排序,顾名思义,就是通过将两个有序的序列合并为一个大的有序的序列的方式来实现排序。合并排序是一种典型的分治算法:首先将序列分为两部分,然后对每一部分进行
众所周知,归并排序的时间复杂度是O(N*lgN) 归并排序的时间复杂度推导书上网上一抓一把,但是多数证明都是基于N=2k这个假设来证明的,下面我给出一般情况的证明。 先上归
