
 手机网站
手机网站
手机网站
手机网站
1 对文本数据进行预处理:数据预处理,包括简繁体转换,去除xml符号,将单词条内容处理成单行数据,word2vec训练原理是基于词共现来训练词之间的语义联系的。不同词条内容需
该资源主要参考我的博客:word2vec词向量训练及中文文本相似度计算其中包括C语言的Word2vec源代码(从官网下载),自定义爬取的三大百科(百度百科、互动百科、维基百科)
word2vec来源 Google开源 可以在百万数量级的词典和上亿的数据集上进行高效地训练 该工具得到的训练结果– 词向量(word embedding),可以很好地度量词与词之间的相似性
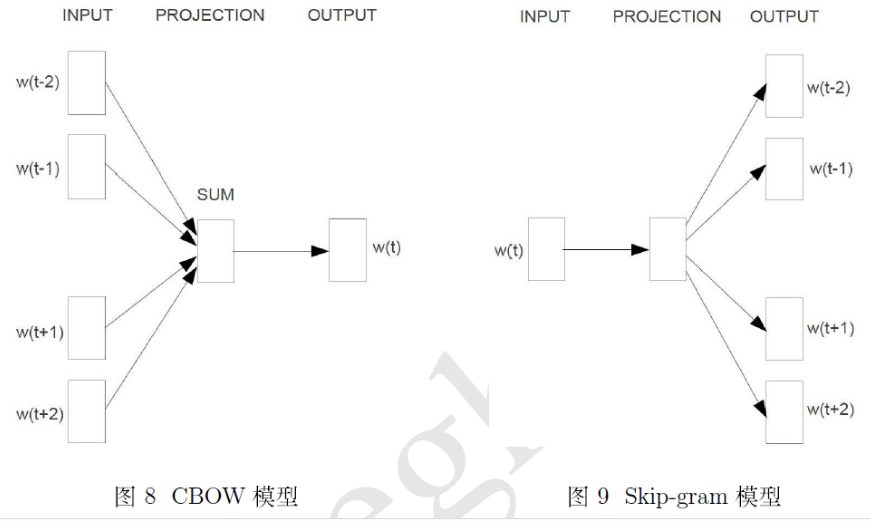
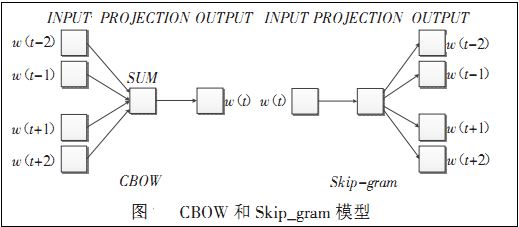
Word2vec是Google公司在2013年开放的一款用于训练词向量的软件工具。它依据给定的语料库,通过优化后的训练模型高速有效的将一个词语表达成向量形式,其核心架构包含
在word2vec中就是采用分布式表征,在向量维数比较大的情况下,每一个词都可以用元素 在一个训练实例中,为每一个词输出词向量代价是非常大的,所以我们提供了两种优雅的
本文是在windows下使用word2vec求词向量(linux环境下,网上有很多,就不再累赘) 1. 因为 修改demo-word.sh文件,该文件默认情况下使用自带的text8数据进行训练,如果训练数据
1 对文本数据进行预处理:数据预处理,包括简繁体转换,去除xml符号,将单词条内容处理成单行数据,word2vec训练原理是基于词共现来训练词之间的语义联系的。不同词条内容需
前言word2vec是如何得到词向量的?这个问题比较大。从头开始讲的话,首先有了文本语料库,你需要对语料库进行预处理,这个处理流程与你的语料库种类以及个人目的有关,比如,如果是英文语料库你可能需要大小写转换检查拼写错误等操作,如果是中文日语语料库你需要增加分词处理。这个过程其他的答案已经梳理过了不再赘述。得到你想要的processed corpus之后,将他们的one-hot向量作为word2vec的输入,通过word2vec训练低维词向量(word embedding)就ok了。不得不说word2vec是个很棒的工具,目前有两种训练模型(CBOW和Skip-gram),两种加速算法(Negative Sample与Hierarchical Softmax)。本答旨在阐述word2vec如何将corpus的one-hot向量(模型的输入)转换成低维词向量(模型的中间产物,更具体来说是输入权重矩阵),真真切切感受到向量的变化,不涉及加速算法。如果读者有要求有空再补上。1 Word2Vec两种模型的大致印象刚才也提到了,Word2Vec包含了两种词训练模型:CBOW模型和Skip-gram
对word2vec数学原理感兴趣的可以移步word2vec 中的数学原理详解,这里就不具体介绍。word2vec对词向量的训练有两种方式,一种是CBOW模型,即通过上下文来预测中心词;另
提纲挈领地讲解 word2vec的理论精髓 学会用gensim训练词向量,并寻找相似词 你不会在 Word2vec 正是来源于这个思想,但它的最终目的,不是要把 f训练得多么完美,而是只关心

word2vec词向量训练及中文文本相似度计算 - 其
661x575 - 73KB - PNG

word2vec词向量训练及中文文本相似度计算
843x503 - 143KB - JPEG

Word2Vec训练词向量全记录
300x240 - 28KB - PNG

word2vec词向量训练及中文文本相似度计算
591x374 - 36KB - JPEG

word2vec词向量训练及中文文本相似度计算 - 其
591x373 - 33KB - JPEG

Word2Vec训练词向量全记录
300x240 - 32KB - PNG

word2vec词向量训练及中文文本相似度计算 - 综
784x457 - 131KB - JPEG

word2vec词向量训练及中文文本相似度计算
661x306 - 45KB - JPEG

金函琪
300x240 - 29KB - PNG
使用tensorflow实现word2vec中文词向量的训练
870x521 - 45KB - JPEG
word2vec词向量训练及中文文本相似度计算
519x227 - 18KB - JPEG

Windows下使用Word2vec持续词向量训练 - W
894x368 - 31KB - PNG

word2vec词向量训练及中文文本相似度计算
592x230 - 27KB - JPEG

Windows下使用Word2vec继续词向量训练,wor
1688x1018 - 74KB - PNG

word2vec词向量训练及中文文本相似度计算_「
592x230 - 26KB - JPEG
