
 手机网站
手机网站
手机网站
手机网站

爬虫Larbin解析(一)--Larbin配置与使用
1136x448 - 53KB - PNG

java后台框架 springmvc整合mybatis框架源码
999x464 - 38KB - PNG

Java爬虫之匿名代理IP的获取
476x268 - 19KB - JPEG

bootstrap后台框架源码 java图片爬虫_「电脑玩
645x373 - 64KB - PNG

Heritrix 跟 Nutch 比较与分析(java开源网络爬虫
552x447 - 34KB - JPEG

Eclipse中Java做网络爬虫基本方法 - 编程大巴
350x665 - 87KB - JPEG

java爬虫爬取美女图片_Java_第七城市
1166x819 - 214KB - JPEG
Java实现爬虫给App提供数据(Jsoup 网络爬虫
1077x828 - 125KB - PNG

Java爬虫实现爬取京东上的手机搜索页面 Http
1227x502 - 173KB - PNG

Java爬虫(一)利用GET和POST发送请求,获取服
869x609 - 71KB - PNG

Java网络爬虫抓取新浪微博个人微博记录_「电
429x343 - 11KB - PNG

Java爬虫(一)利用GET和POST发送请求,获取服
716x520 - 32KB - PNG
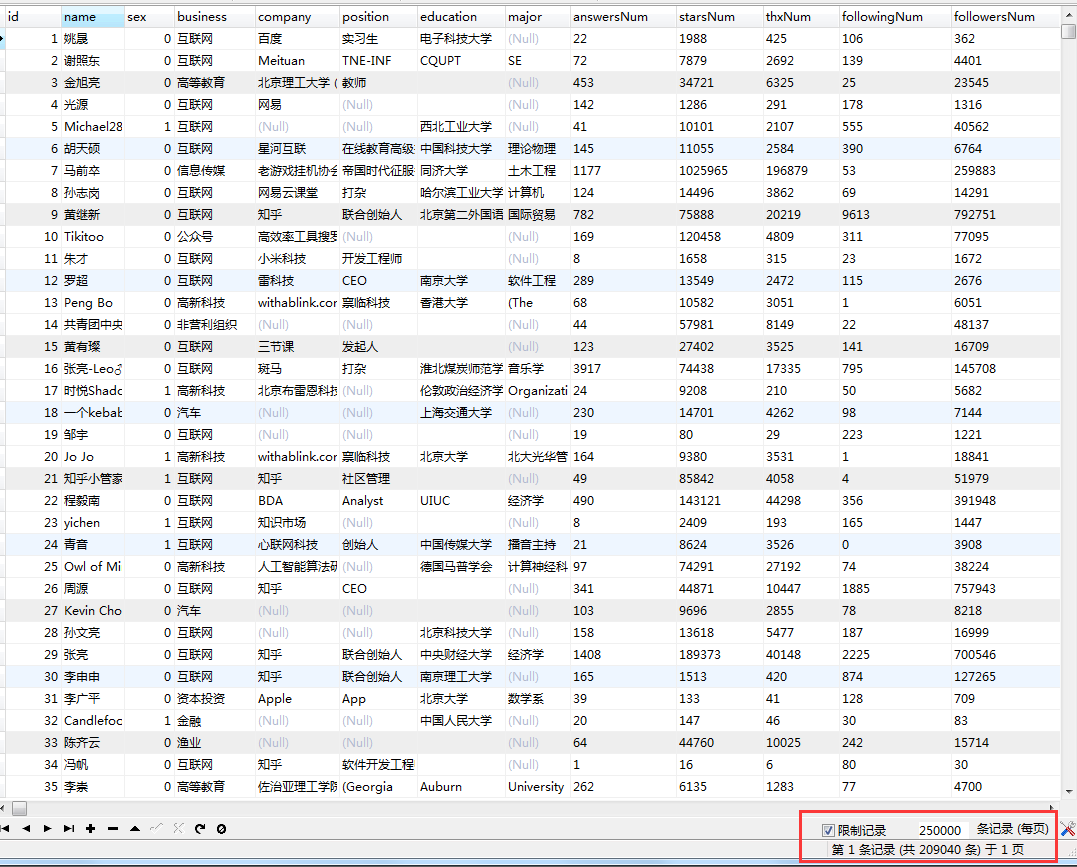
Java爬虫抓取知乎20万用户信息并做简易分析
1077x867 - 173KB - PNG
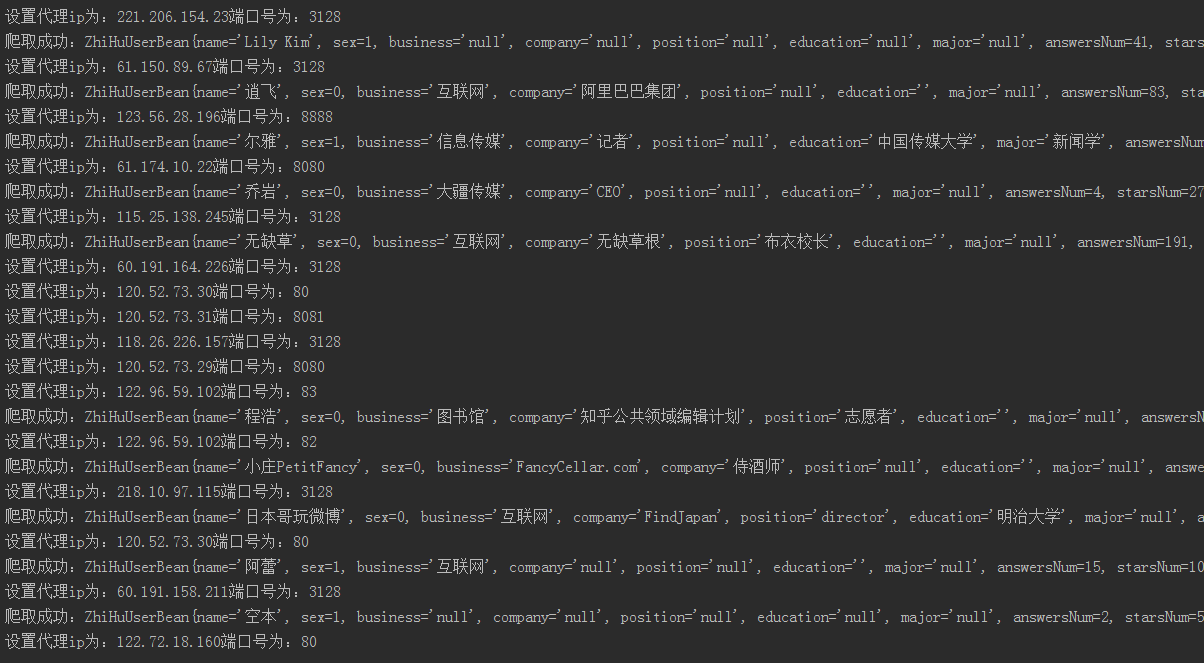
Java爬虫抓取知乎20万用户信息并做简易分析
1204x663 - 109KB - PNG
学习分享-Java爬虫伪代码 - 今日头条(TouTiao
640x259 - 16KB - JPEG
1: 网络爬虫是做什么的?他的主要工作就是跟据指定的url地址去发送请求,获得响应,然后解析响应 ,一方面从响应中查找出想要查找的数据,另一方面从响应中解析出新的URL路径
Ⅰ 在进行网页爬虫前,我们先针对一个飞机事故失事的文档进行数据提取的练习,主要是温习一下上一篇的java知识,也是为了下面爬虫实现作一个热身准备。 首先分析这个文档
Java爬虫入门笔记 2017年03月14日 20:55:26 版权声明:若注明出处,请随意转载。Thank You! 今天一天都在想怎么爬到我需要的数据,然后用Java代码实现了一下。以前只是知
记得在刚找工作时,隔壁的一位同学在面试时豪言壮语曾实现过网络爬虫,当时的景仰之 实现了一个简单但足够用的爬虫系统。 Java网络爬虫的实
之前一节我们说过java爬虫从网络上利用jsoup获取网页文本,也就是说我们可以有三种方法获取html,一是根据url链接,而是从本地路径获取,三是通过字符串解析成html文档 在这里
1.nutch 地址:apache/nutch · GitHub apache下的开源爬虫程序,功能丰富,文档完整。有数据抓取解析以及存储的模块。而且这玩意儿还包括了一个开箱即用的搜索引擎,安装好就可以搜索了。2.Heritrix 地址:internetarchive/heritrix3 · GitHub 很早就有了,经历过很多次更新,使用的人比较多,功能齐全,文档完整,网上的资料也多。有自己的web管理控制台,包含了一个HTTP 服务器。操作者可以通过选择Crawler命令来操作控制台。3.crawler4j 地址:yasserg/crawler4j · GitHub 因为只拥有爬虫的核心功能,所以上手极为简单,几分钟就可以写一个多线程爬虫程序。当然,上面说的nutch有的功能比如数据存储不代表Heritrix没有,反之亦然。具体使用哪个合适还需要仔细阅读文档并配合实验才能下结论啊~还有比如JSpider,WebEater,Java Web Crawler,WebLech,Ex-Crawler,JoBo等等,这些没用过,不知道。。。 ps:来 前任网 骂一骂前任
学习java爬虫,1天后开始出现明显效果 刚开始先从最简单的爬虫逻辑入手 爬虫最简单的解析面真的是这样 1 import org.jsoup.Jsoup; 2 import org.jsoup.nodes.Document; 3 impo
原 java爬虫入门实战 JeffCoding 阅读数:17892 2016-11-11 版权声明:本文为博主原创文章,未经博主允许不得转载。 爬虫 百度百科:网络爬虫(又被称为网页蜘蛛,网络机器人,在
上一篇写了一个简单的新浪新闻爬虫作为上手主要是用jsoup包来对url页面进行抓取到本地,并在本地进行数据的解析提取。这里就不重复叙述jsoup的用法了,百度一下基本一大
