
 手机网站
手机网站
手机网站
手机网站

网站换ip已经6天了,新服务器还不见百度蜘蛛,要
480x360 - 24KB - JPEG

百度蜘蛛爬虫如何判断网站访问速度的相关因
833x762 - 83KB - JPEG

百度蜘蛛爬虫如何判断网站访问速度的相关因
833x762 - 114KB - JPEG
百度的爬虫为什么可以访问Facebook? - 搜索引
547x308 - 62KB - JPEG
淘宝为什么禁止百度爬虫但是用户还是能搜到呢
640x400 - 14KB - JPEG
哪些网站优化的细节会影响百度爬虫的抓取与百
366x220 - 18KB - JPEG
纯干货-影响百度爬虫对网站抓取量的四大因素
525x217 - 11KB - JPEG

使用 Python 编写多线程爬虫抓取百度贴吧邮箱
1920x1080 - 204KB - JPEG
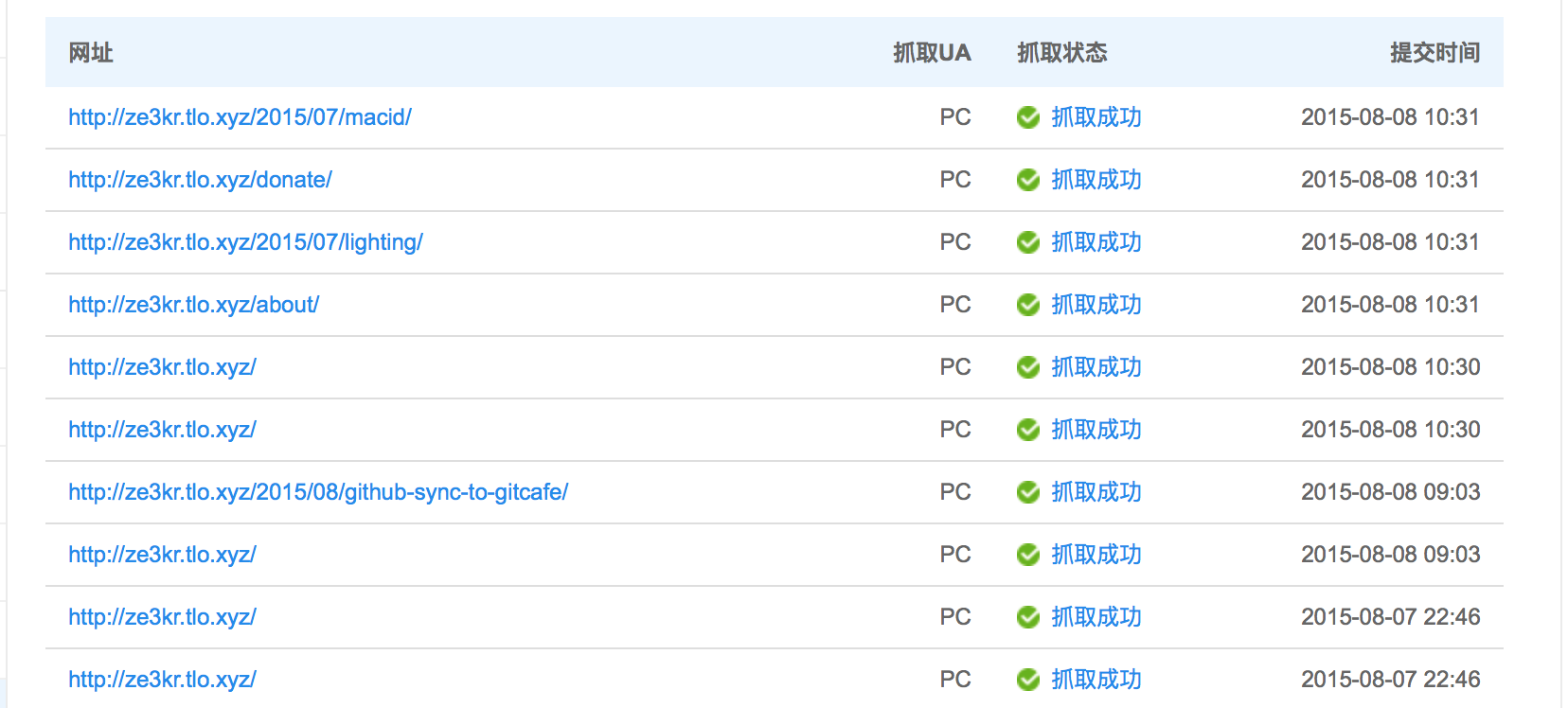
如何解决百度爬虫无法爬取搭建在Github上的个
1656x748 - 205KB - PNG
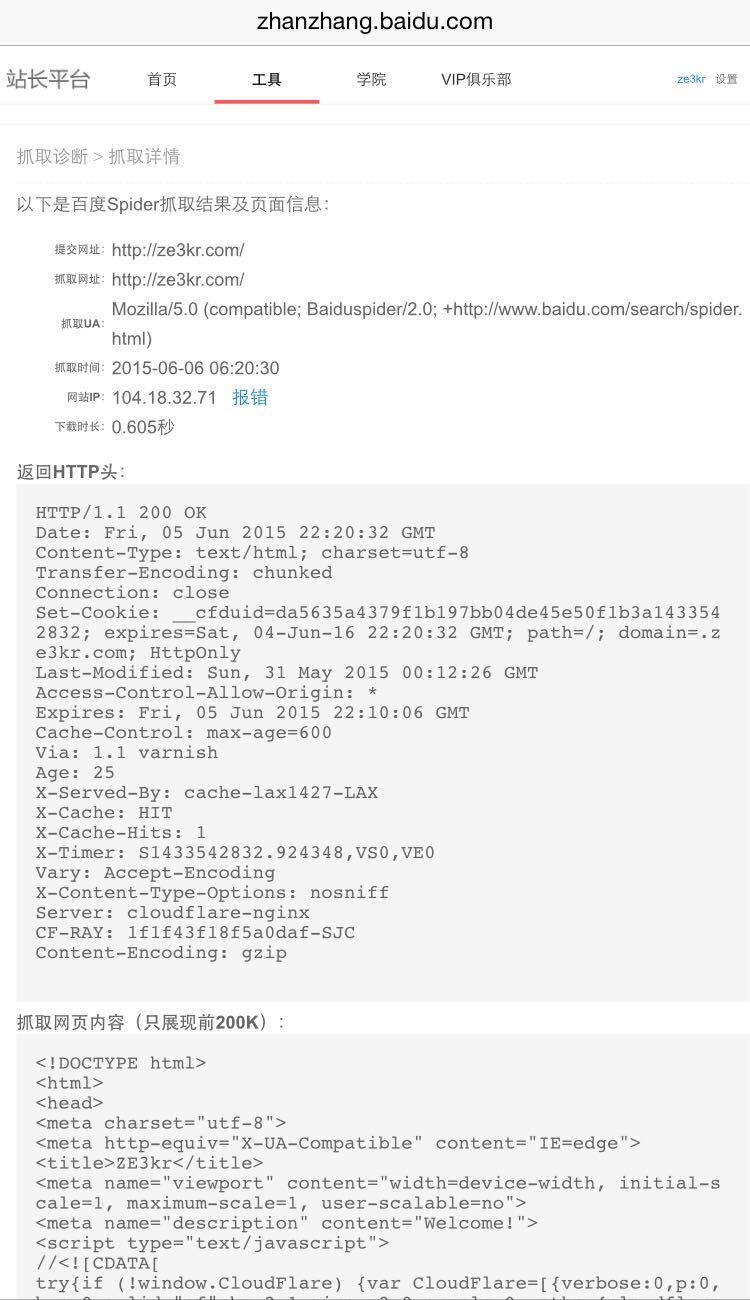
如何解决百度爬虫无法爬取搭建在Github上的个
750x1300 - 115KB - JPEG
如何解决百度爬虫无法爬取搭建在Github上的个
1610x750 - 128KB - PNG
如何解决百度爬虫无法爬取搭建在Github上的个
750x700 - 31KB - JPEG

爬虫大战百度影音,百度影音电影,邻居大战2百
1099x555 - 30KB - PNG

零基础写python爬虫之抓取百度贴吧并存储到本
667x599 - 19KB - PNG

如何利用python写爬虫程序_百度知道
600x333 - 206KB - PNG
简介:网络爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。网络爬虫为搜索引擎从万维网下载网页
简介:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规
中国网民用的搜索引擎最主要的就是百度了,所以我们做seo的要学会让百度更好的喜欢我们的网站。也只有这样我们的网站才能运营下去。做SEO如何让百度爬虫更喜欢你呢
百度是搜索引擎,爬虫就是沿着网站的链接不断搜索,并下载到本地的机器人程序。 搜索引擎在一定程度上会给网站造成负担。 所以现在有很多网站都有反爬虫设置,把自己想要被搜索出的东西直接提供给爬虫,而不让爬虫去抢占带宽。
专业文档是百度文库认证用户/机构上传的专业性文档,文库VIP用户或购买专业文档下载特权礼包的其他会员用户可用专业文档下载特权免费下载专业文档。了解文档类型 www
原来是百度的爬虫不断的抓取分类页面的,筛选链接。官方的的筛选链接没有加rel= nofollow 3、在相关页面加上rel= nofollow 后,清空缓存。仍然无效。修改nginx的配置,禁止Ba
屏蔽百度爬虫的方法 2009-4-4 9:24:18 | 作者:月光 |分类: 网站建设| 评论: 62 |浏览: 在百度C2C产品“百度有啊”即将上线的时候,淘宝网站曾经屏蔽百度搜索爬虫,禁止百度搜索
class crawler: '''爬百度搜索结果的爬虫''' url = u'' urls = o_urls = html = '' total_pages = 5 current_page = 0 next_page_url = '' timeout = 60 #默认超时时间为60秒 headersParamete
百度爬虫抓取太厉害,每天50多万,服务器不动了,怎么办? 37,676 次浏览 百度爬虫抓取太厉害了,怎么办? 我的服务器是5M带宽。 百度每天抓取50多万。导致我的服务器都动不
八爪鱼百度教程分类为你提供百度各类数据爬虫以及采集教程,具体包括百度地图采集、百度关键词采集、百度图片采集等文章,让你轻松的采集百度数据。 实战教程 旗舰版+Q
