
 手机网站
手机网站
手机网站
手机网站
交 叉 熵 损 失 函 数 chyang1999|2018-06-30 (高于99%的文档) 马上扫一扫 手机打开 随时查看 手机打开 专业文档 专业文档是百度文库认证用户/机构上传的专业性文档,文库V
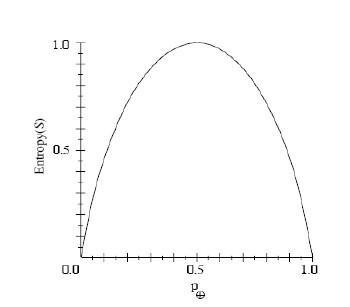
熵,交叉熵和损失函数,在机器学习中,这些概念容易让人迷糊,基于现有的理解,简要做一下总结供参考,以后理解深刻了,在进行拓展。 熵作为一种测量信息量的一个度量,可以用意
在TensorFlow中,已经有实现好softmax函数,所以我们可以自己构造交叉熵损失函数: import tensorflow as tf import input_data x = tf.placeholder( float , shape=[None, 784]) label =
可能会有读者说,我已经知道了交叉熵损失函数的推导过程。但是能不能从更直观的角度去理解这个表达式呢?而不是仅仅记住这个公式。好问题!接下来,我们从图形的角度,分析
交叉熵损失函数 \[ loss =\sum_{i}{(y_{i} \cdot log(y\_predicted_{i}) +(1-y_{i}) \cdot log(1-y\_predicted_{i}) )} \] 关于交叉熵 在信息论中,若一个符号字符串中的每个字符的出现概率\
简介:语言模型的性能通常用交叉熵和复杂度(perplexity)来衡量。交叉熵的意义是用该模型对文本识别的难度,或者从
另外,交叉熵函数的形式是−[ylna+(1−y)ln(1−a)]而不是 −[alny+(1−a)ln(1−y)],为什么?因为当期望输出的y=0时,lny没有意义;当期望y=1时,ln(1-y)没有意义。而因为a是sigmoid函
#交叉熵损失函数 #数据 y = np.array([[0, 1], [1, 0], [1, 0]]) yhat = np.array([[.5, .5], [.5, .5], [.5, .5]]) #转换为张量 y_tensor = tf.convert_to_tensor(y, dtype=tf.int32) yhat_tensor = tf.con
交叉熵就不是为了解决梯度消失的……他只是分类问题中极大似然估计自然导出的一个损失函数而已。用sigmoid在交叉熵之前只是为了构造一个 (0,1) 区间内的数用来表示一个概率。这种做法就只是logistics回归的形式到了神经网络里面的利用而已。
logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。 例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。
简单易懂的softmax交叉熵损失函数求导
640x231 - 8KB - JPEG
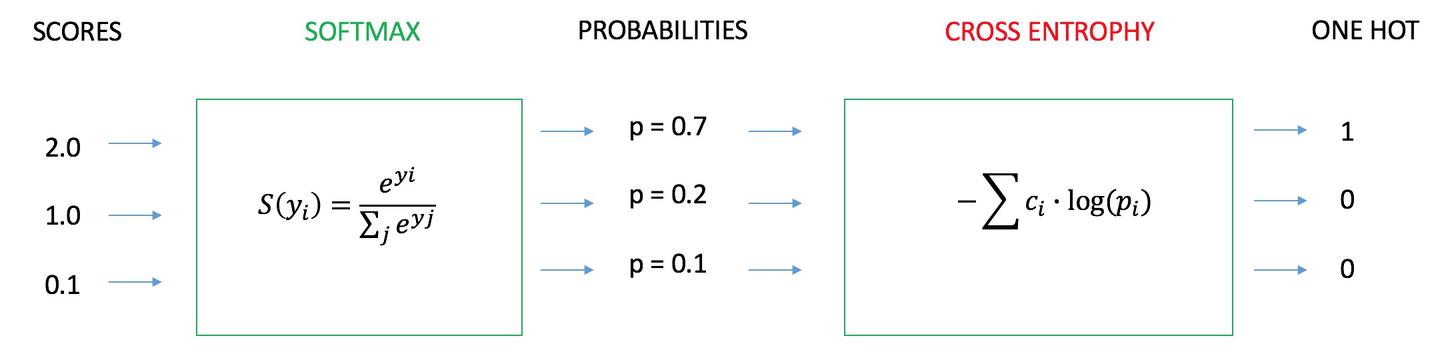
损失函数--交叉熵损失函数
1200x500 - 48KB - JPEG

为什么逻辑回归的损失函数叫做交叉熵呢?
1081x721 - 121KB - JPEG
简单易懂的softmax交叉熵损失函数求导
640x475 - 29KB - JPEG
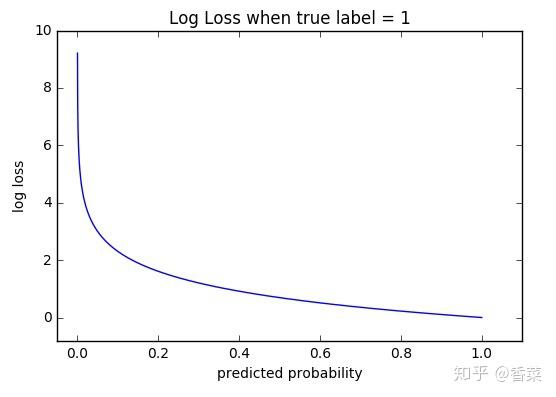
损失函数--交叉熵损失函数
556x397 - 22KB - JPEG

交叉熵损失函数
678x260 - 47KB - PNG
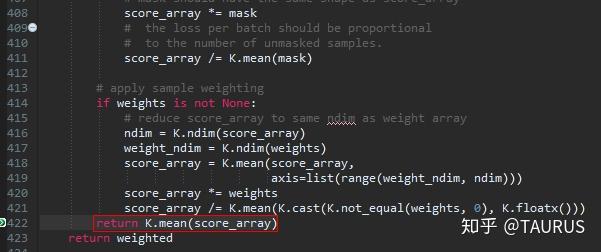
keras中两种交叉熵损失函数的探讨
350x307 - 6KB - JPEG

交叉熵损失函数
588x260 - 29KB - PNG
keras中两种交叉熵损失函数的探讨
601x252 - 48KB - JPEG
交叉熵作为分类任务的损失函数,去掉log是否可
842x750 - 69KB - JPEG

交叉熵损失函数 - 蓝讯
280x220 - 4KB - PNG
交叉熵作为分类任务的损失函数,去掉log是否可
842x750 - 73KB - JPEG

交叉熵损失函数 - 蓝讯
280x220 - 5KB - PNG
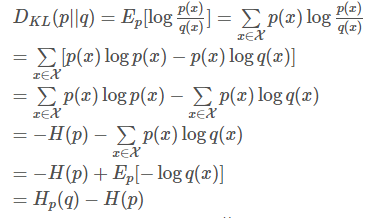
机器学习最常用的损失函数之交叉熵
369x218 - 29KB - PNG

交叉熵损失函数 - 蓝讯
280x220 - 34KB - PNG
