
 手机网站
手机网站
手机网站
手机网站
可能会有读者说,我已经知道了交叉熵损失函数的推导过程。但是能不能从更直观的角度去理解这个表达式呢?而不是仅仅记住这个公式。好问题!接下来,我们从图形的角度,分析
平均交叉熵应该是先计算batch中每一个样本的交叉熵后取平均计算得到的,而利用tf.reduce_mean函数其实计算的是整个矩阵的平均值,这样做的结果会有差异,但是并不改变实际
交叉熵损失函数的求导 这步需要用到一些简单的对数运算公式,这里先以编号形式给出,下面推导过程中使用特意说明时都会在该步骤下脚标标出相应的公式编号,以保证推导的
并提供了tf.nn.softmax_cross_entropy_with_logits函数。比如可以直接通过以下代码实现了sotfmax回归之后的交叉熵损失函数: cross_entropy=tf.nn.sparse_sotfmax_cross_entro
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一
请. 1.前言在机器学习中学习模型的参数是通过不断损失函数的值来实现的。对于机器学习中常见的损失函数有:平方损失函数与交叉熵损失函数。在本文中将讲述两者含义与响
在Quora Question Pairs比赛中,我们的目标是判断给定的两个问题的语义信息是否相同(即是否为重复问题),使用的评估标准是log loss,交叉熵损失函数 \[ \frac{1}{N}\sum_{i=0}^{N
另外,交叉熵函数的形式是−[ylna+(1−y)ln(1−a)]而不是 −[alny+(1−a)ln(1−y)],为什么?因为当期望输出的y=0时,lny没有意义;当期望y=1时,ln(1-y)没有意义。而因为a是sigmoid函
损失函数可以有很多形式,这里用的是交叉熵函数,主要是由于这个求导结果比较简单,易于计算,并且交叉熵解决某些损失函数学习缓慢的问题。交叉熵的函数是这样的: C = -\sum
交 叉 熵 损 失 函 数 chyang1999|2018-06-30 (高于99%的文档) 马上扫一扫 手机打开 随时查看 手机打开 专业文档 专业文档是百度文库认证用户/机构上传的专业性文档,文库V
简单易懂的softmax交叉熵损失函数求导
640x231 - 8KB - JPEG
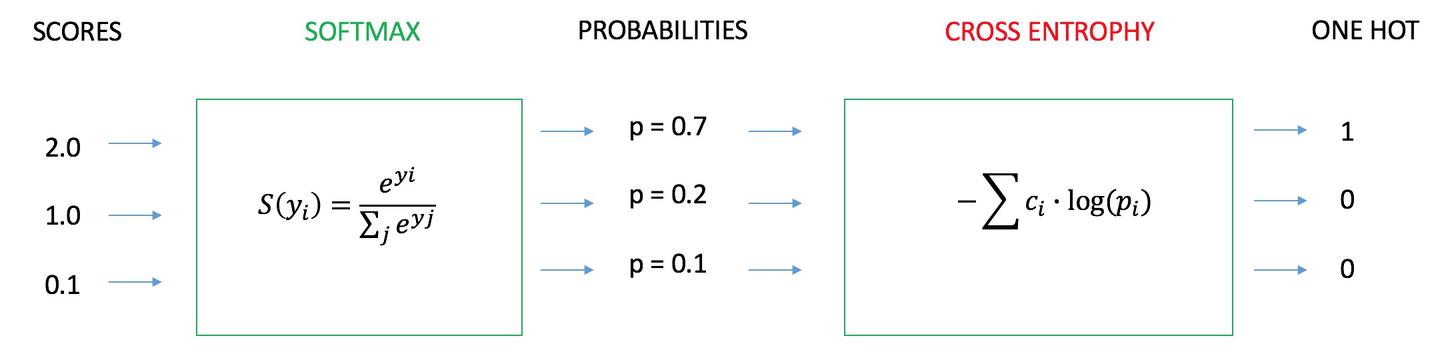
损失函数--交叉熵损失函数
1200x500 - 48KB - JPEG
简单易懂的softmax交叉熵损失函数求导
640x475 - 29KB - JPEG
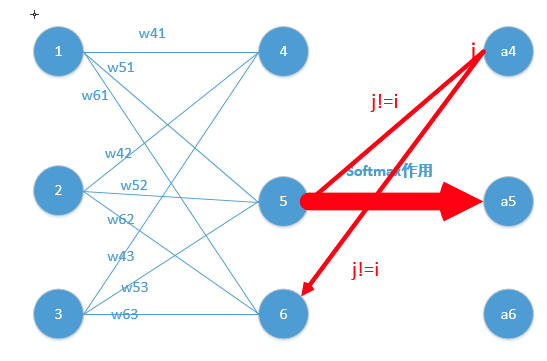
Softmax 函数的特点和作用是什么?
547x361 - 43KB - PNG
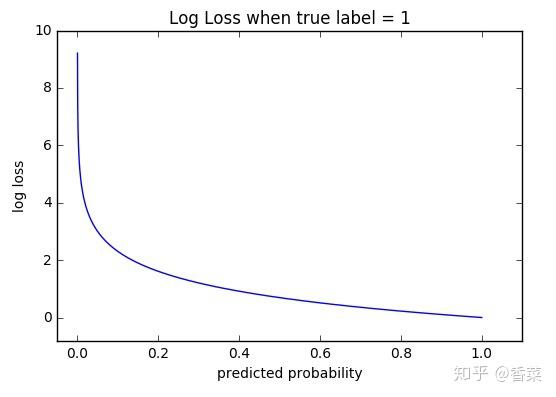
损失函数--交叉熵损失函数
556x397 - 22KB - JPEG
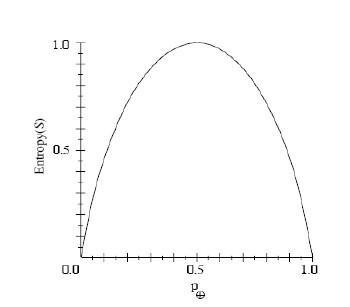
keras中两种交叉熵损失函数的探讨
350x307 - 6KB - JPEG

交叉熵损失函数
678x260 - 47KB - PNG

交叉熵损失函数
588x260 - 29KB - PNG
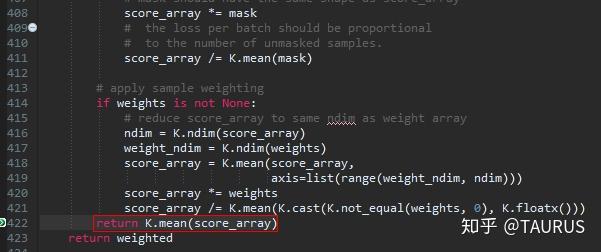
keras中两种交叉熵损失函数的探讨
601x252 - 48KB - JPEG
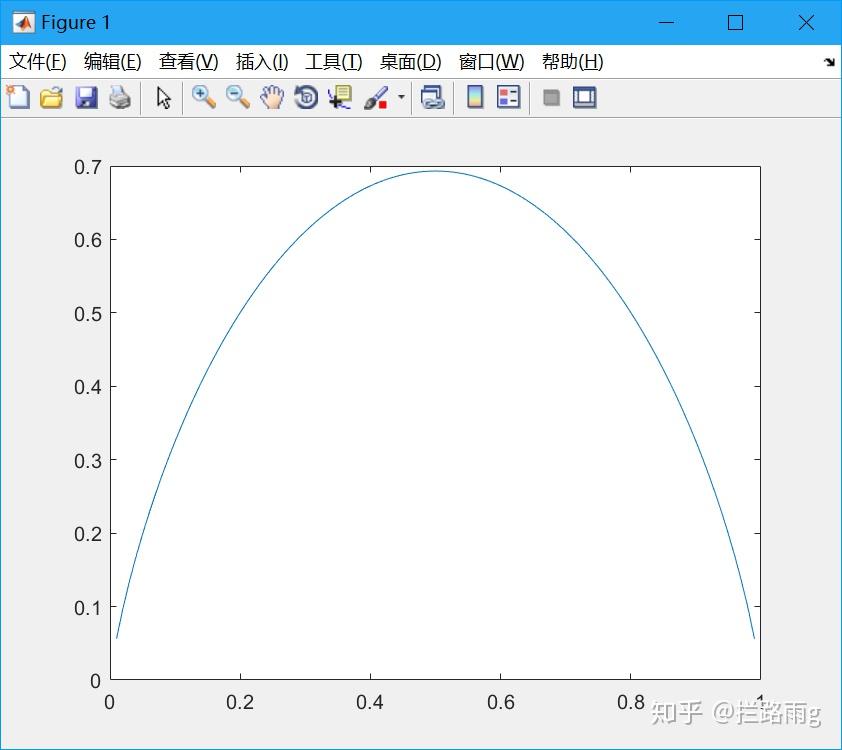
交叉熵作为分类任务的损失函数,去掉log是否可
842x750 - 69KB - JPEG

为什么逻辑回归的损失函数叫做交叉熵呢?
1081x721 - 121KB - JPEG

交叉熵损失函数 - 蓝讯
280x220 - 4KB - PNG
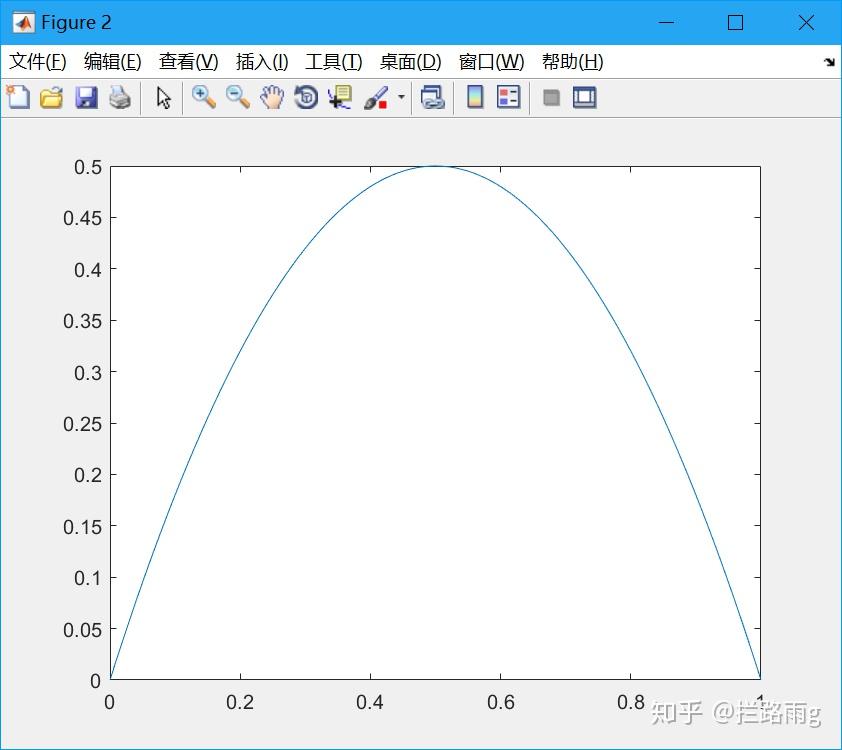
交叉熵作为分类任务的损失函数,去掉log是否可
842x750 - 73KB - JPEG

交叉熵损失函数 - 蓝讯
280x220 - 5KB - PNG
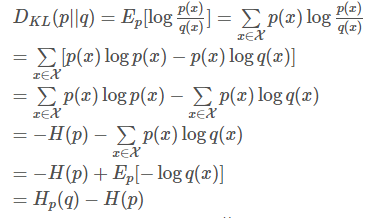
机器学习最常用的损失函数之交叉熵
369x218 - 29KB - PNG
