
 手机网站
手机网站
手机网站
手机网站
常使用交叉熵作为loss对模型的参数求梯度进行更新,那为何交叉熵能作为损失函数呢,我也是带着这个问题去找解析的。 以下仅为个人理解,如有不当地方,请读到的看客能指出
序前面介绍了二分类与多分类情况下交叉熵损失的不同以及原因,但是在二分类中,逻辑回归的交叉熵损失函数同样具有两种形式,其原因是由类别取值所导致的。类别取值为0和
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交
交叉熵损失函数对 \(\widehat{y}_i\) 求导,得到 \[\frac{1-y_i}{1-\widehat{y}_i} = \frac{y_i}{\widehat{y}_i}\] 当 \(y_i = \widehat{y}_i\) 时可以得到损失函数的最小值。 当训练和测试的数
交 叉 熵 损 失 函 数 chyang1999|2018-06-30 (高于99%的文档) 马上扫一扫 手机打开 随时查看 手机打开 专业文档 专业文档是百度文库认证用户/机构上传的专业性文档,文库V
本文使用纯 Python和 PyTorch对比实现cross-entropy交叉熵损失函数及其反向传播. 相关 原理和详细解释,请参考文章 : 通过案例详解cross-entropy交叉熵损失函数 系列文章索引
nerualnetworkanddeeplearning学习_交叉熵损失函数 2018年01月04日 14:28:12 salaslyrin阅读数:293 版权声明:本文为博主原创文章,未经博主允许不得转载。 交叉熵损失函数
简介:语言模型的性能通常用交叉熵和复杂度(perplexity)来衡量。交叉熵的意义是用该模型对文本识别的难度,或者从
经常是喜欢用二次代价函数来做损失函数,因为比较通俗易懂,后面在大部分的项目实践中却很少用到二次代价函数作为损失函数,而是用交叉熵作为损失函数。为什么?一直在思
本文主要介绍了交叉熵损失函数的数学原理和推导过程,也从不同角度介绍了交叉熵损失函数的两种形式。第一种形式在实际应用中更加常见,例如神经网络等复杂模型;第二种多
简单易懂的softmax交叉熵损失函数求导
640x231 - 8KB - JPEG
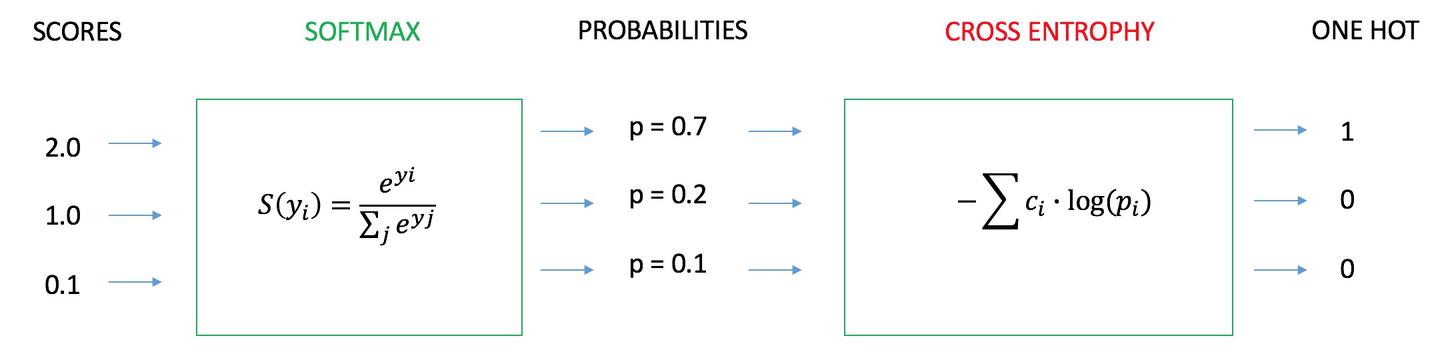
损失函数--交叉熵损失函数
1200x500 - 48KB - JPEG
简单易懂的softmax交叉熵损失函数求导
640x475 - 29KB - JPEG
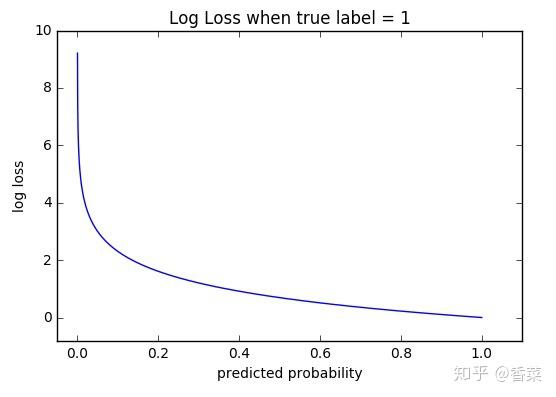
损失函数--交叉熵损失函数
556x397 - 22KB - JPEG

交叉熵损失函数
678x260 - 47KB - PNG

交叉熵损失函数
588x260 - 29KB - PNG
keras中两种交叉熵损失函数的探讨
601x252 - 48KB - JPEG
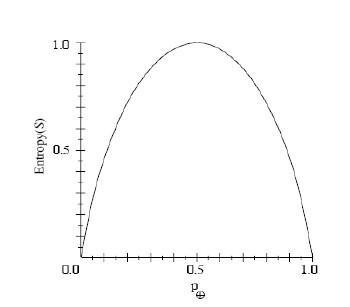
keras中两种交叉熵损失函数的探讨
350x307 - 6KB - JPEG
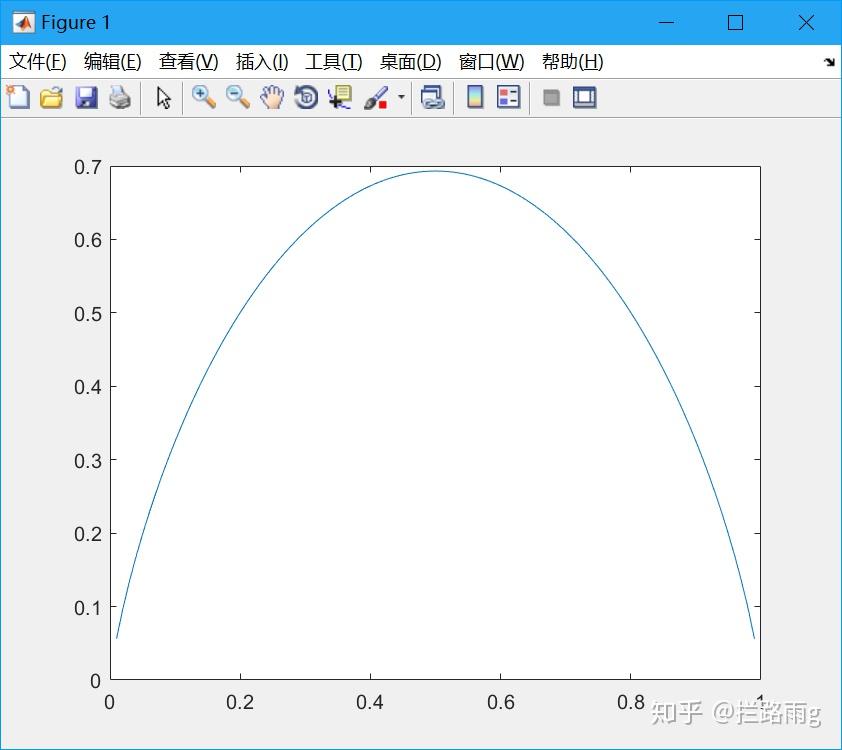
交叉熵作为分类任务的损失函数,去掉log是否可
842x750 - 69KB - JPEG

为什么逻辑回归的损失函数叫做交叉熵呢?
1081x721 - 121KB - JPEG

交叉熵损失函数 - 蓝讯
280x220 - 4KB - PNG
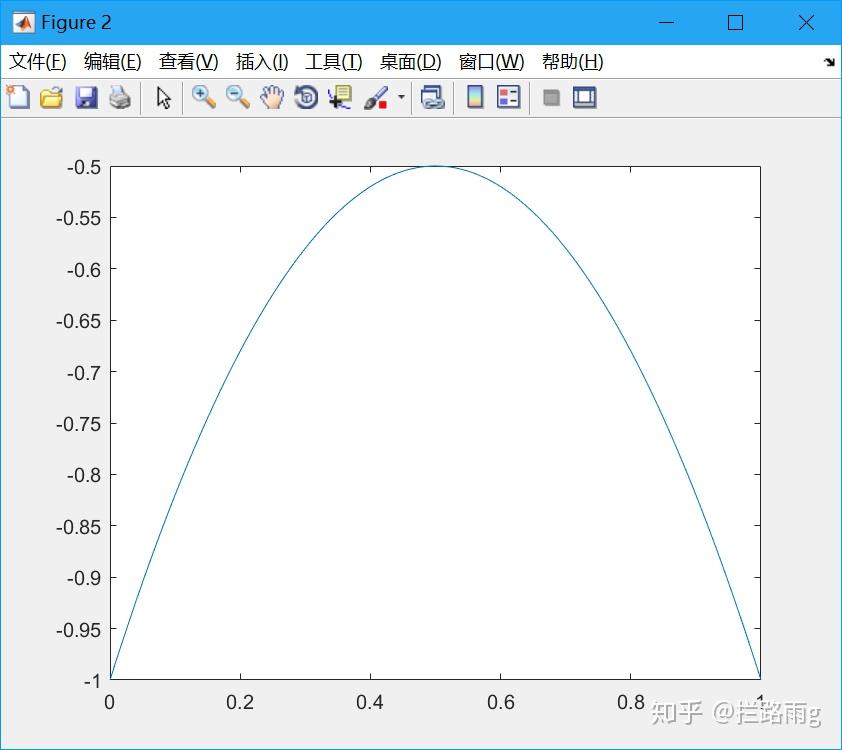
交叉熵作为分类任务的损失函数,去掉log是否可
842x750 - 73KB - JPEG

交叉熵损失函数 - 蓝讯
280x220 - 5KB - PNG

理解交叉熵作为损失函数在神经网络中的作用_
578x194 - 20KB - PNG

交叉熵损失函数 - 蓝讯
280x220 - 34KB - PNG
