
 手机网站
手机网站
手机网站
手机网站
交叉熵为1.75 - 1.5 = 0.25,大于0,表示预测结果与真实结果之间存在差异,这里的差异便是中国队和哥斯达黎加队的预测结果。不难看出,交叉熵的值越大,这种差异程度也就越大。
请听题:什么是熵?什么是交叉熵?什么是联合熵?什么是条件熵?什么是相对熵?它们的联系与区别是什么?如果你感到回答这些问题有些吃力,对这些概念似乎清楚,似乎又没有那
它表示2个函数或概率分布的差异性:差异越大则相对熵越大,差异越小则相对熵越小,特别 交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模
也就是A与B的交叉熵。得证,交叉熵可以用于计算“学习模型的分布”与“训练数据分布”之间的不同。当交叉熵最低时(等于训练数据分布的熵),我们学到了“最好的模型”。
需要说明的是,交叉熵的值越大,这种差异程度也就越大。 在二分类模型中,由于目标的可能性有两种,因此需要分别计算预测为正例和负例概率下的交叉熵,公式为: =−[ylogy′+(
它表示2个函数或概率分布的差异性:差异越大则相对熵越大,差异越小则相对熵越小,特别 交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模
简介:语言模型的性能通常用交叉熵和复杂度(perplexity)来衡量。交叉熵的意义是用该模型对文本识别的难度,或者从
通过上面的描述和介绍,我们应该很高兴使用交叉熵来比较两个分布y,y`之间的不同,然后我们可以用所有训练数据的交叉熵的和来作为我们的损失,假如用n来表示我们训练数据的
第一种交叉熵损失函数的形式: H(p,q)=−∑xp(x)logq(x) 假设N=3,期望输出为p=(1,0,0),实际输出 q1=(0.5,0.2,0.3),q2=(0.8,0.1,0.1) ,这里的q1,q2两个输出分别代表在不同的神经网
后面在大部分的项目实践中却很少用到二次代价函数作为损失函数,而是用交叉熵作为损失函数。为什么?一直在思考这个问题,这两者有什么区别,那个更好?下面通过数学的角度
交叉熵作为分类任务的损失函数,去掉log是否可
842x750 - 69KB - JPEG

基于小波多尺度和熵在图像字符特征提取方法的
508x239 - 13KB - PNG

基于交叉熵的出租车资源合理配置.PDF
800x1131 - 278KB - PNG

采用交叉熵支持向量机和模糊积分的电网故障诊
600x872 - 148KB - JPEG

基于交叉熵的病毒式移动通信系统性能研究-控
800x1131 - 71KB - PNG

交叉熵相似性度量在水文时间序列匹配中的应用
800x1098 - 360KB - PNG
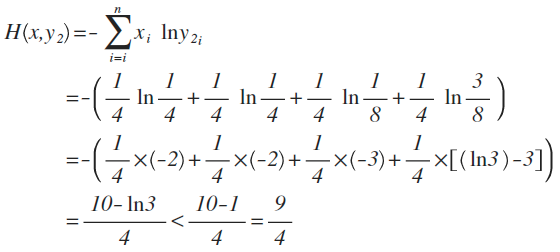
归一化(softmax)、信息熵、交叉熵
560x252 - 26KB - PNG

基于信息熵的DEA交叉效率综合评价.pdf
800x1098 - 455KB - PNG

二维最大类间交叉熵阈值分割法
1435x2110 - 1519KB - PNG
学界 | Tomaso Poggio深度学习理论:深度网络「
1080x464 - 36KB - JPEG

交叉熵图像处理.ppt
1280x720 - 113KB - PNG

基于交叉熵理论的配电变压器寿命组合预测方法
800x1131 - 60KB - PNG

基于量子粒子群优化算法的最小交叉熵多阈值图
800x1217 - 382KB - PNG

基于交叉熵的正态分布区间数多属性决策方法.
800x1156 - 367KB - PNG

为什么逻辑回归的损失函数叫做交叉熵呢?
1081x721 - 121KB - JPEG
