
 手机网站
手机网站
手机网站
手机网站
爬虫的主要目的是将互联网上的网页下载到本地形成一个互联网内容的镜像备份。这里主要对爬虫以及抓取系统进行一个简单的概述。一、网络爬虫的基本结构及工作流程一
网络爬虫是捜索引擎抓取系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份。这篇博客主要对爬虫以及抓取系统进行一个
网络爬虫是捜索引擎抓取系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份。这篇博客主要对爬虫以及抓取系统进行一个
网络爬虫工作原理 我若成风JL|2018-07-02 |举报 网络爬虫工作原理 专业文档 专业文档是百度文库认证用户/机构上传的专业性文档,文库VIP用户或购买专业文档下载特权礼包
工作原理:网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,
网络爬虫基本原理 cybercity|2015-09-07 |举报 专业文档 专业文档是百度文库认证用户/机构上传的专业性文档,文库VIP用户或购买专业文档下载特权礼包的其他会员用户可用专
简介:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规
在了解Scrapy爬虫原理及框架的基础上,本节简要介绍Scrapy爬虫框架的数据采集过程。 随着互联网信息的与日俱增,利用网络爬虫工具来获取所
《精通Python网络爬虫:核心技术、框架与项目实战》第3章网络爬虫实现原理与实现技术,在这一章中,我们将学习网络爬虫的实现原理及其实现技术
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁,自动索引,模拟程序或者蠕虫. 网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。 相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题: (1) 对抓取目标的描述或定义; (2) 对网页或数据的分析与过滤; (3) 对UR
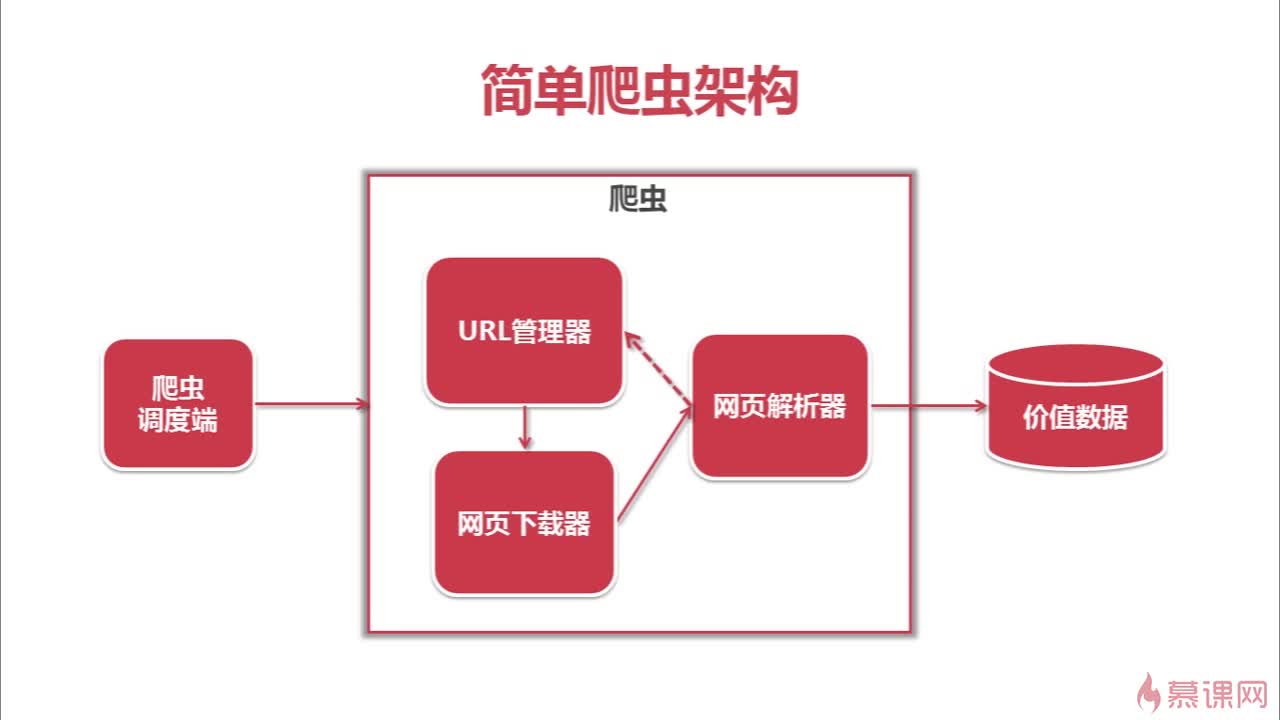
使用Python2.7写网络爬虫-1
1280x720 - 43KB - JPEG

如何设计爬虫架构
670x342 - 27KB - JPEG

一名合格的数据分析师分享Python网络爬虫二三
345x336 - 47KB - JPEG

网络信息分类:原理与应用\/施国良
500x751 - 54KB - JPEG

网络爬虫基本原理(一)
600x364 - 35KB - PNG
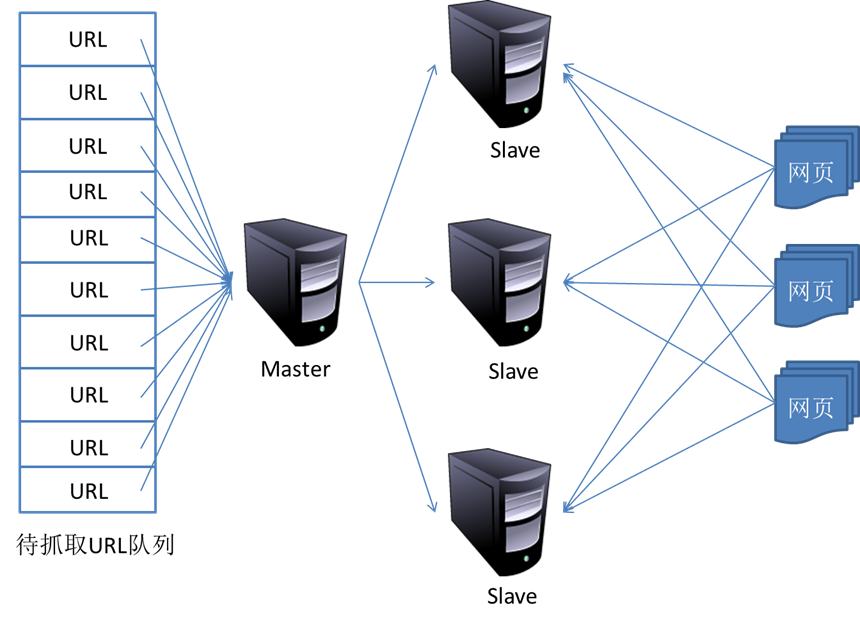
网络爬虫基本原理(二) :更新策略与分布式抓取
860x625 - 159KB - PNG

《包邮 精通Scrapy网络爬虫 计算机 程序设计
350x350 - 16KB - JPEG
![[c#搜片神器]+之p2p中dht网络爬虫原理](http://www.cxyclub.cn/Upload/Images/2013072514/F1885A2C0CDF1B9B.jpg)
[c#搜片神器]+之p2p中dht网络爬虫原理
1168x762 - 223KB - JPEG

网络爬虫简单原理_「电脑玩物」中文网我们只
921x603 - 103KB - PNG

网络爬虫与Web安全 - 目录 - 关于我们 - H3C
552x281 - 10KB - PNG

网络爬虫基本原理(一)_科技IT_南阳新闻_南阳
335x414 - 25KB - PNG

网络爬虫基本原理(一)
892x398 - 109KB - PNG

网络爬虫基本原理.doc
141x200 - 14KB - PNG
Python网络爬虫基本原理 - 今日头条(www.touti
640x396 - 20KB - JPEG

网络爬虫基本原理.doc
794x1123 - 52KB - PNG
