
 手机网站
手机网站
手机网站
手机网站
金羊网讯记者黄珏报道:通过网络点餐已是觉的餐饮服务方式,但如何对网络端口进行食品安全的监管呢?2月12日,记者从珠海市食药监局获悉,该局在省内率先利用网络 爬虫 技术
Ferret 是一个声明式的 Web爬虫系统,旨在简化网络上的数据提取,以用于 UI测试、机器学习和分析等等。 Ferret拥有自己的声明式语言,通过抽象出技术细节和底层技术的复杂性
GooSeeker网络爬虫软件-免费网页抓取软件,抓取网页上的数据,存成excel表格,用于行业研究,市场分析,电商竞争分析,抓取商品价格和图片,自动分词软件用于毕业设计和文本
八爪鱼网页数据采集器,是一款使用简单、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网络数据抓取,连续四年大数据行业数据采集领域
简介:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面
网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需
最近我们在做类似的工作,一方面接单独的定制需求,另一方面做一个无需编程的智能云爬虫网站。可以来我们这里看看:造数 - 最好用的云爬虫工具我们精心制作了视频:造数云爬虫使用教程- 因为刚开始三周左右,还有很多项目需要大家的意见来完善。我们现在可以满足的范例如下: 比如你看到这样的网站,信息很多,但你只想要一个excel表,告诉你地址,大小,总价和均价。 网址粘到我们低调的首页搜索框以后,选择你要哪一类数据,选一个,同类的就帮你选上了。 最后你会得到下面这样的列表:注册好以后我们会给你生成一个控制台,然后选择你喜欢的格式输出就好了。Excel也好,csv,json也罢,统统没问题。
网络爬虫一直是很热的话题,行业标杆Google,Baidu,这都不用多说了,网络爬虫就是为其提供信息来源的程序。对于当时的我接触这个东西还是一脸懵逼,也怀疑这些大公司开发
这是一个网络爬虫学习的技术分享,主要通过一些实际的案例对爬虫的原理进行分析,达到对爬虫有个基本的认识,并且能够根据自己的需要爬到想要的数据。有了数据后可以做
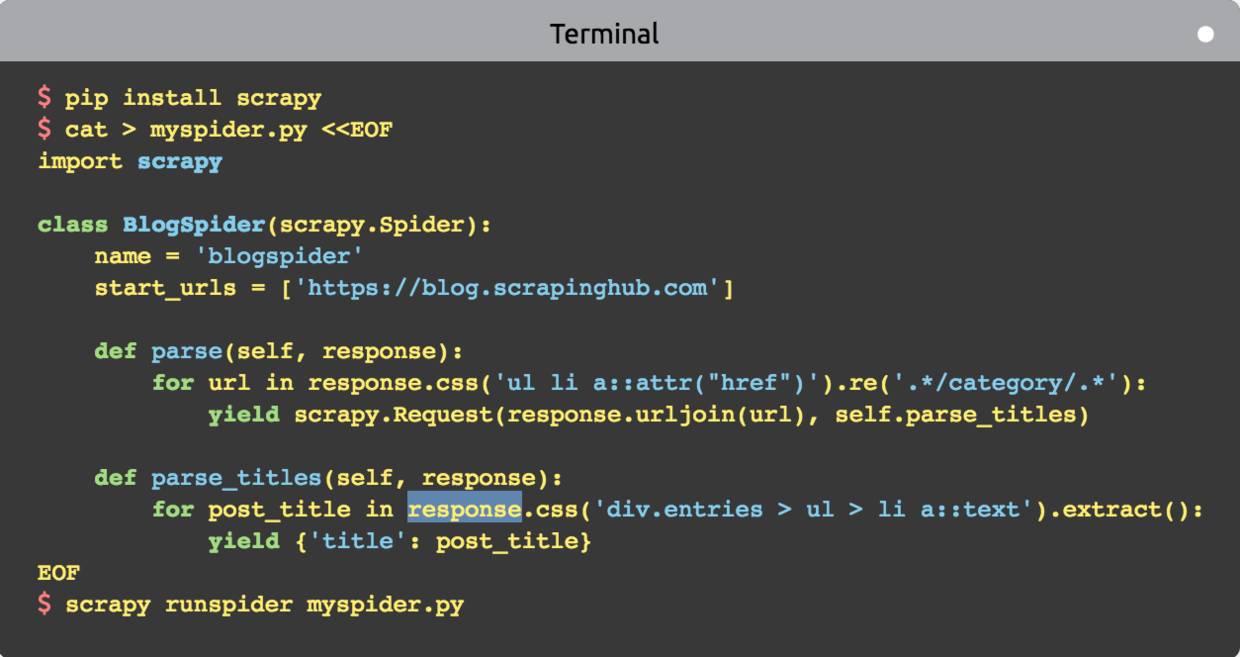
网络爬虫:使用 Scrapy 框架编写一个抓取书籍信息的爬虫服务-搜狐
1240x657 - 57KB - JPEG

Scrapy网络爬虫框架实际案例讲解,Python爬虫原来如此简单!_【快资讯】
640x426 - 35KB - JPEG

疏重于堵 如何应对网络爬虫流量很重要-科技频道-和讯网
500x259 - 31KB - JPEG
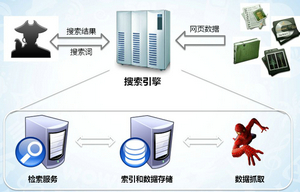
网络爬虫的应用
300x192 - 66KB - JPEG

疏重于堵 如何应对网络爬虫流量很重要-科技频道-和讯网
500x500 - 76KB - JPEG
使用Python2.7写网络爬虫-1
1280x720 - 43KB - JPEG

eritrix 跟 Nutch 比较与分析(java开源网络爬虫)_
600x452 - 43KB - JPEG

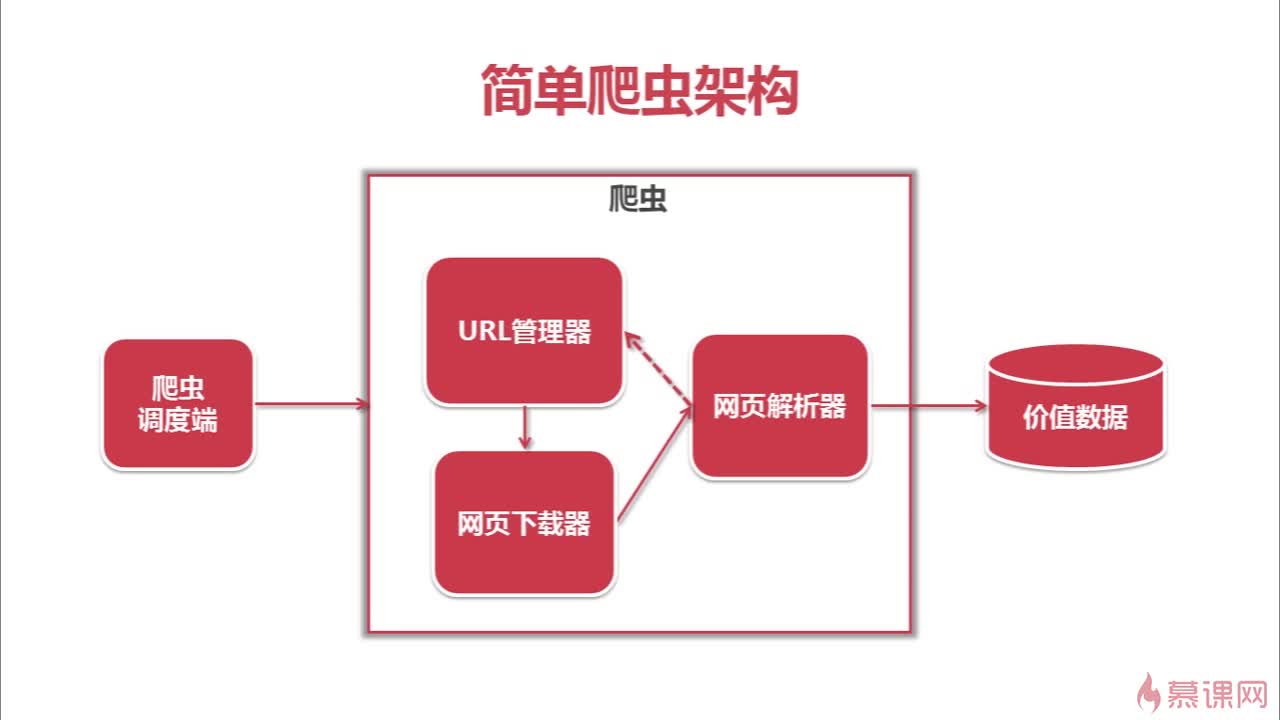
如何设计爬虫架构
670x342 - 27KB - JPEG
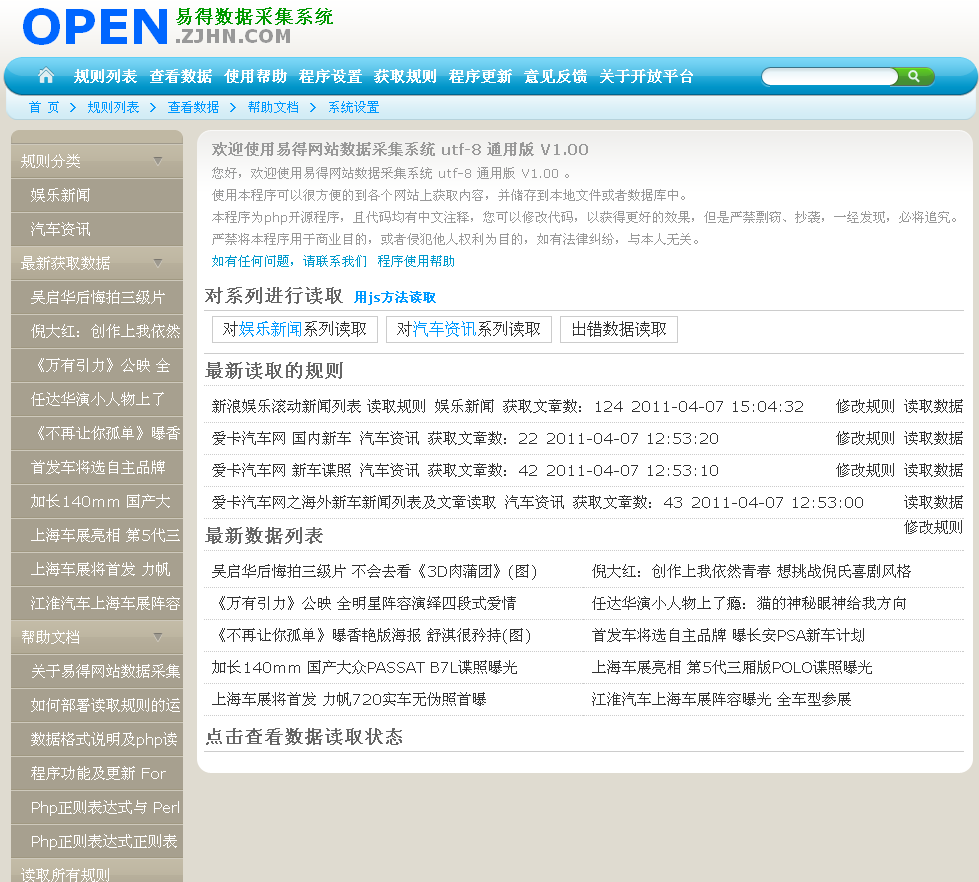
易得网络数据采集系统的类似软件 - 网络爬虫
979x882 - 72KB - PNG
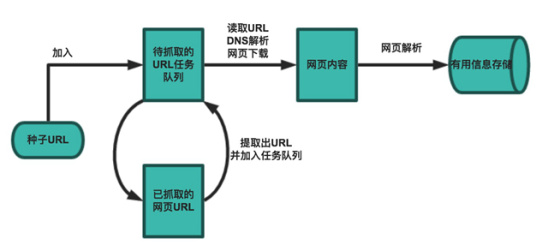
python编写知乎爬虫实践
550x251 - 24KB - JPEG

亚马逊黑科技深挖,卖家都好奇的爬虫技术!
750x386 - 67KB - JPEG
搜索引擎的网络爬虫、网页蜘蛛爬行知识分享,
640x335 - 18KB - JPEG

网络爬虫框架Scrapy简介 - 综合编程类其他综合
629x340 - 66KB - PNG

数据采集 商业数据 软件开发 采集 网络爬虫 客
300x300 - 55KB - JPEG

Python项目教程:即时网络爬虫项目启动说明_第
597x268 - 19KB - PNG
