
 手机网站
手机网站
手机网站
手机网站

Scrapy报400和415错误
678x260 - 13KB - JPEG

使用scrapy框架爬取自己的博文(2) - huhuuu-Py
600x386 - 202KB - PNG

使用scrapy框架爬取自己的博文(2) - huhuuu
550x354 - 207KB - PNG

使用scrapy框架爬取自己的博文(2) - 编程大巴
1064x684 - 39KB - PNG

python scrapy的一点杂谈 - Python开发技术文章
831x544 - 19KB - JPEG

Centos7 Python3下安装scrapy的详细步骤
700x435 - 71KB - PNG

Scrapy: 10分钟写一个爬虫抓取美女图
640x319 - 11KB - JPEG

Python_1024
300x240 - 57KB - PNG
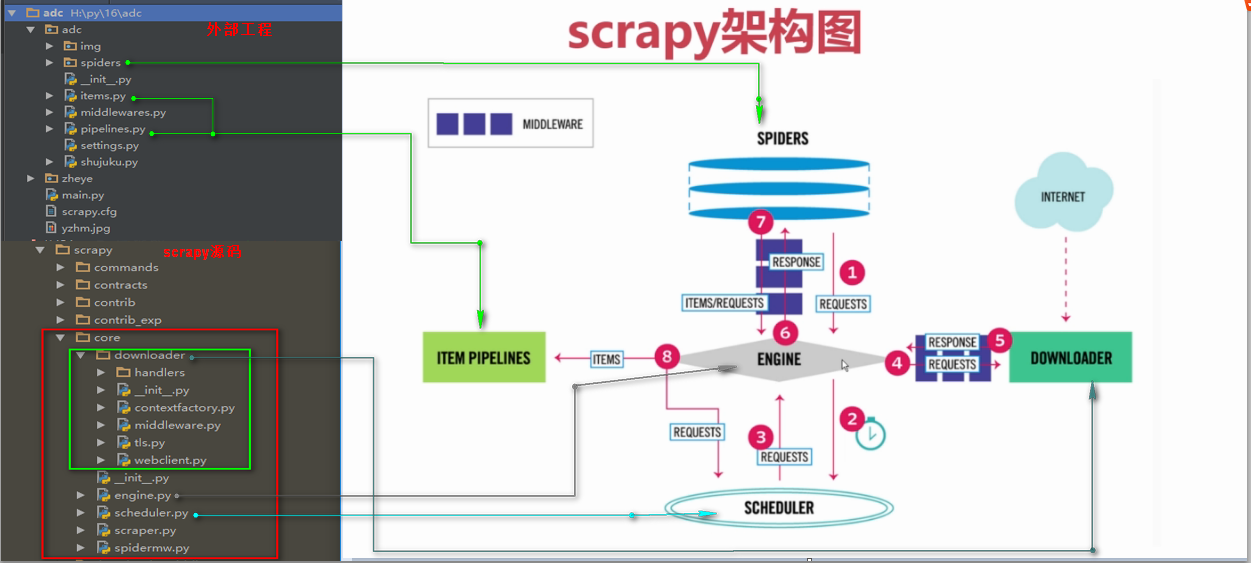
十四 Python分布式爬虫打造搜索引擎Scrapy精
1251x563 - 215KB - PNG
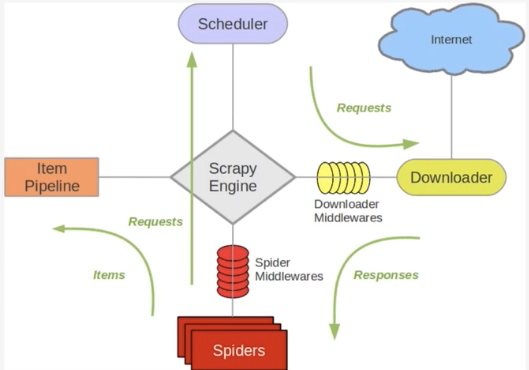
Python爬虫从入门到放弃(二十)之 Scrapy分布式
529x370 - 124KB - PNG

Python scrapy 实现网页爬虫 - Python开发技术
721x305 - 36KB - PNG

pip install scrapy 报错_Python_第七城市
984x471 - 67KB - PNG
大白话Scrapy爬虫
601x404 - 23KB - JPEG
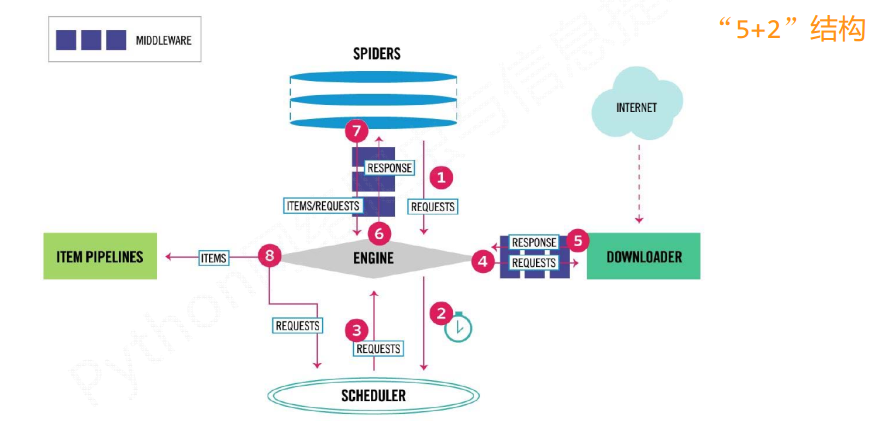
Mooc爬虫05-scrapy框架-布布扣-bubuko.com
889x440 - 163KB - PNG

hon程序员用的是同样是爬虫框架,为何Scrapy深
1236x748 - 416KB - PNG
scrapy 出现400 Bad Request 问题 遇到400解决思路:1.检查url连接,有的url最后有’/’有的没有,看看
用scrapy.Request()方法请求一个url地址,发现返回400错误,我检查了我不是被封ip,把请求链接直接copy到
17:11:59[scrapy.core.engine]DEBUG:Crawled(400)(referer:一 四口之家三人都有听说障碍,却
想要实现Scrapy爬我今天爬手机APP也遇到了这个400错误,我把formdata改成了formdata=json.dumps(formdata)
400,'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware':500,'scrapy.downloadermiddlewares.
[scrapy.pipelines.files]WARNING:File(code:400):Error downloading file from<GET xxx>referred in
400,'scrapy.downloadermiddlewares.retry.RetryMiddleware':500,'scrapy.downloadermiddlewares.
爬取某个网站的时候,遇到一个报400错误的问题。在爬取该网站上的网页时,把scrapy中的cookie设置为false.
请求带网址是' https://www.investing.com/ins ',使用一模一样带headers和data,scrapy返回400
