
 手机网站
手机网站
手机网站
手机网站
爬取网站时请求被拒绝?scrapy轻松解决请求头
610x475 - 41KB - JPEG

爬取网站时请求被拒绝?scrapy轻松解决请求头
636x431 - 32KB - JPEG
爬取网站时请求被拒绝?scrapy轻松解决请求头
640x452 - 34KB - JPEG

爬取网站时请求被拒绝?scrapy轻松解决请求头
640x398 - 24KB - JPEG

爬取网站时请求被拒绝?scrapy轻松解决请求头
551x458 - 30KB - JPEG
scrapy发送payload方式的post请求
1667x655 - 70KB - PNG

爬取网站时请求被拒绝?scrapy轻松解决请求头
397x300 - 16KB - JPEG

爬取网站时请求被拒绝?scrapy轻松解决请求头
294x300 - 14KB - JPEG

一篇文章就够打通python网络请求,scrapy爬虫,
641x1032 - 51KB - JPEG

python scrapy的一点杂谈 - Python开发技术文章
831x544 - 19KB - JPEG

Scrapy: 10分钟写一个爬虫抓取美女图
640x319 - 11KB - JPEG

Centos7 Python3下安装scrapy的详细步骤
700x435 - 71KB - PNG

Python_1024
300x240 - 57KB - PNG
十四 Python分布式爬虫打造搜索引擎Scrapy精
1251x563 - 215KB - PNG
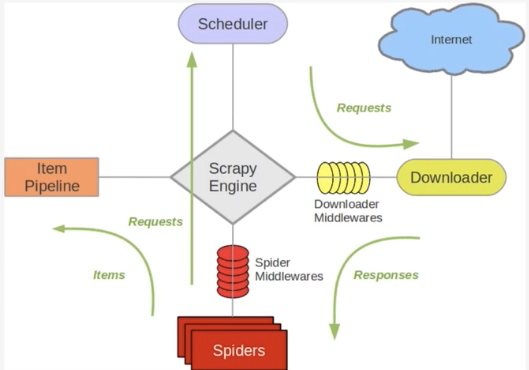
Python爬虫从入门到放弃(二十)之 Scrapy分布式
529x370 - 124KB - PNG
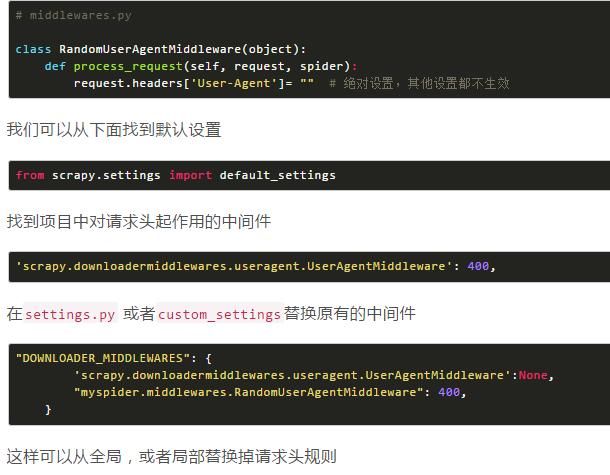
重写scrapy内置的UserAgentMiddleware.MIDDLEWARES,将系统默认的随机请求头给禁掉,再添加我们自己定义的
scrapy设置”请求池”引言相信大家有时候爬虫发出请求的时候会被ban,返回的是403错误,这个就是请求头的
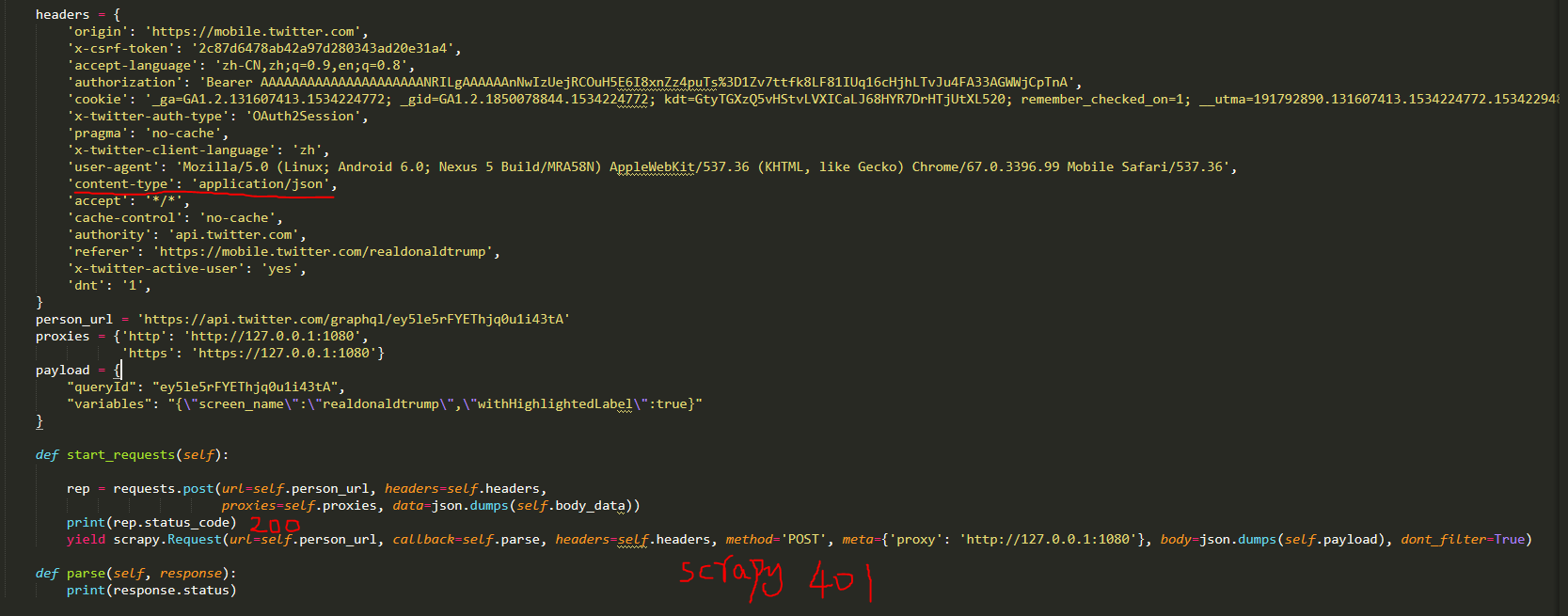
def start_requests(self):login_url='要请求的链接'#发送post请求 data={} yield scrapy.FormRequest(url=
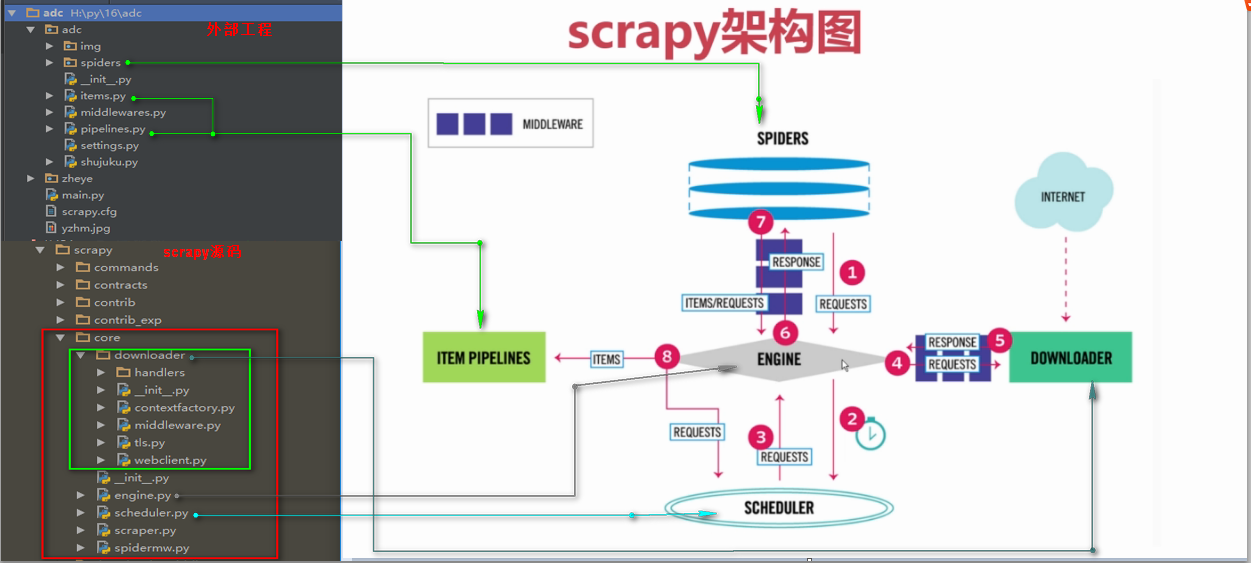
此dict对于新请求为空,通常由不同的Scrapy组件(扩展程序,中间件等)填充。因此,此dict中包含的数据取决
在处理请求时引发任何异常时将 调用 的函数。import scrapy from scrapy.spidermiddlewares.httperror
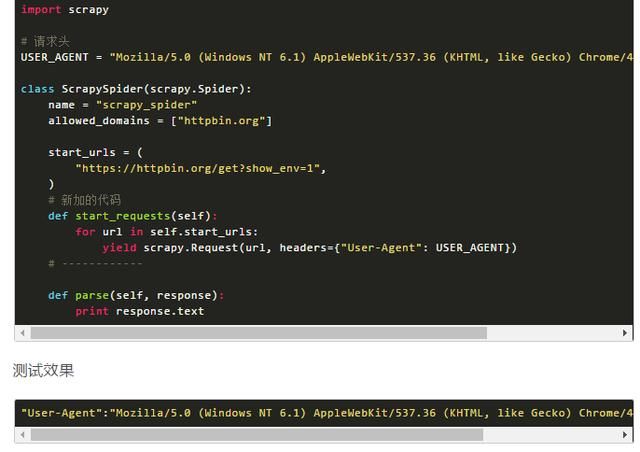
当我们大量使用scrapy 请求一个网站的时候我们知道scrapy默认的请求头是:可以看到默认的请求头就是scrapy
默认请求头命令行执行,新建爬虫scrapy startproject myspider cd myspider scrapy genspider scrapy_
阅读数:128 标签:Scrapy 此时fp指纹集合中已经存在了该指纹,再次启动该项目时,因为设置了请求去重,
请求头中多了Scrapy… User-Agent":"Scrapy/1.1.2(+http://scrapy.org),Mozilla/5.0(Windows NT 6.1)
coding:utf-8-*-import scrapy from_9gag.items import GagItem class FirstSpider(scrapy.Spider):name=
