
 手机网站
手机网站
手机网站
手机网站
为什么要获取到网页的HTML时需要在展开全部 获取文本信息,如果不加的话只返回你一个HTTP状态码,可以使用
''' 超时参数的使用 response=requests.get(url,timeout=3)通过添加timeout参数,能够保证在3秒钟内返回
二、requests.get方法的使用: 要爬取的网站:“https://b.faloo.com/l/0/1.html?t=1&k=%CB%D9%B6%C8” 爬
Header可以通过Request提供的.add_header()方法进行添加,示例代码如下: 123456789101112#-*-coding:utf-8
2.requests.get()方法使用 所谓的get方法,便是利用程序使用HTTP协议中的GET请求方式对目标网站发起请求,
r=requests.get(url,headers=headers) 传递 cookies url=' http://httpbin.org/cookies ' r=requests.get
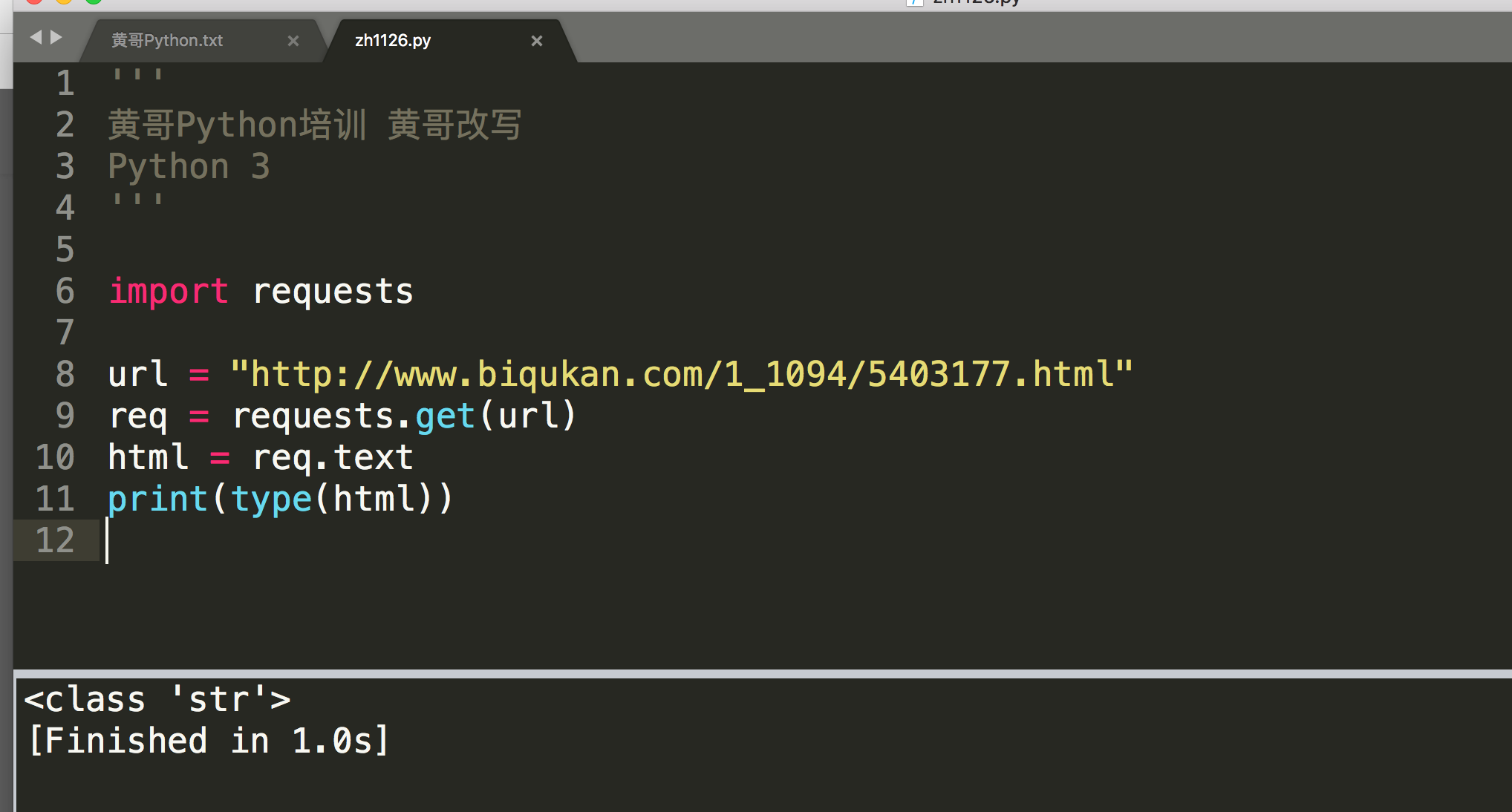
python requests.get后网页中文全是ascii编码?
2036x1094 - 159KB - JPEG
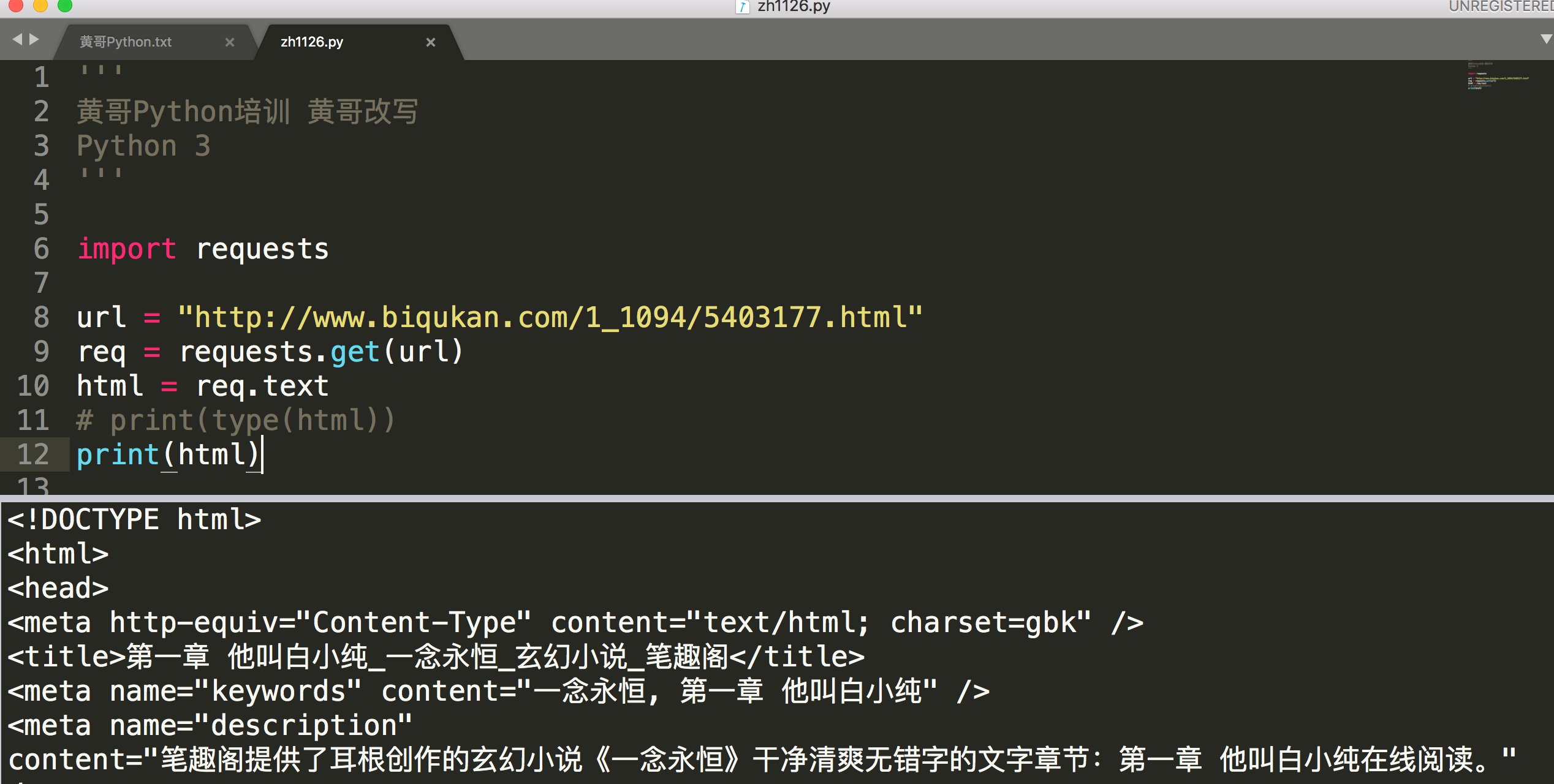
python requests.get后网页中文全是ascii编码?
2536x1280 - 372KB - JPEG
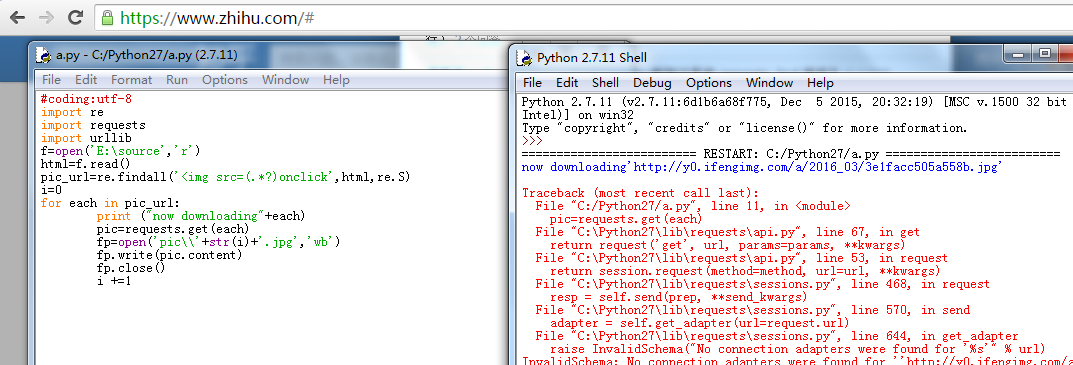
requests.get不能使用怎么解决? - Python
1073x365 - 68KB - PNG

python接口自动化20-requests获取响应时间(el
973x612 - 48KB - PNG
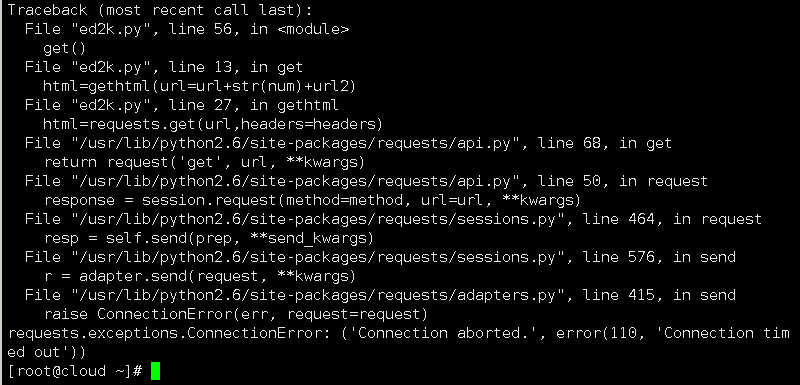
Python在用requests库下载图片时,有的时候抛异
800x385 - 15KB - PNG

Python爬虫知识1.1 requests库的安装与使用
600x568 - 88KB - JPEG

Python的requests网络编程包使用教程_神马软
448x539 - 83KB - PNG

python打造渗透工具集
924x664 - 96KB - JPEG

Python学习:用requests-html抓彩票数据
550x236 - 80KB - PNG
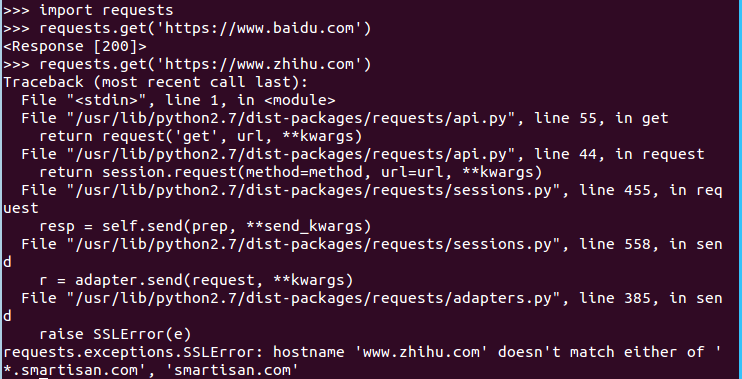
使用Python爬取知乎内容时,老是出现如下错误
742x379 - 65KB - PNG
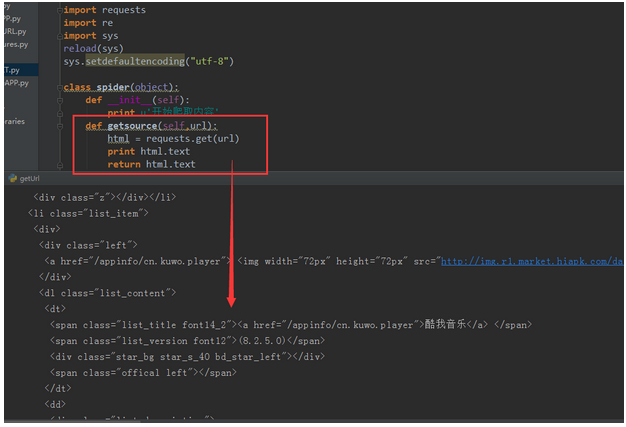
Python爬取APP下载链接的实现方法 - PHPER
626x427 - 117KB - PNG

Python爬虫工程师教你爬取最简单(美女)的教程
637x529 - 43KB - JPEG

Python 装饰器实现的retry 出错重试_「电脑玩物
586x262 - 70KB - JPEG

【实战练习】Python3网络爬虫快速入门实战解
2521x1239 - 560KB - JPEG
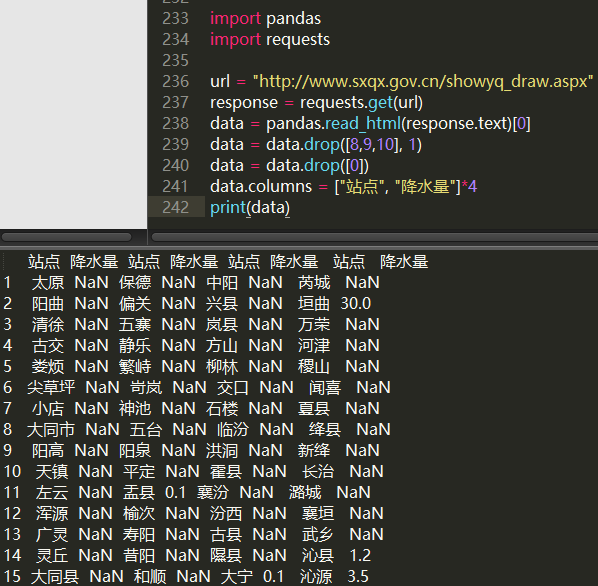
python爬虫表格里面的数据应该怎样抓?
598x586 - 85KB - PNG
