
 手机网站
手机网站
手机网站
手机网站

微软分析Pypi数据: 5月21日Python3战胜Pytho
640x270 - 21KB - JPEG

微软分析Pypi数据: 5月21日Python3战胜Pytho
377x265 - 10KB - JPEG

学习python3连载系列-2启动Python的方法有哪
640x250 - 24KB - JPEG

学习python3连载系列-2启动Python的方法有哪
300x300 - 8KB - JPEG

Python3 程式库参考手册
270x270 - 14KB - JPEG

千锋欧阳大神Python3基础视频教程免费赠送啦
569x240 - 213KB - PNG
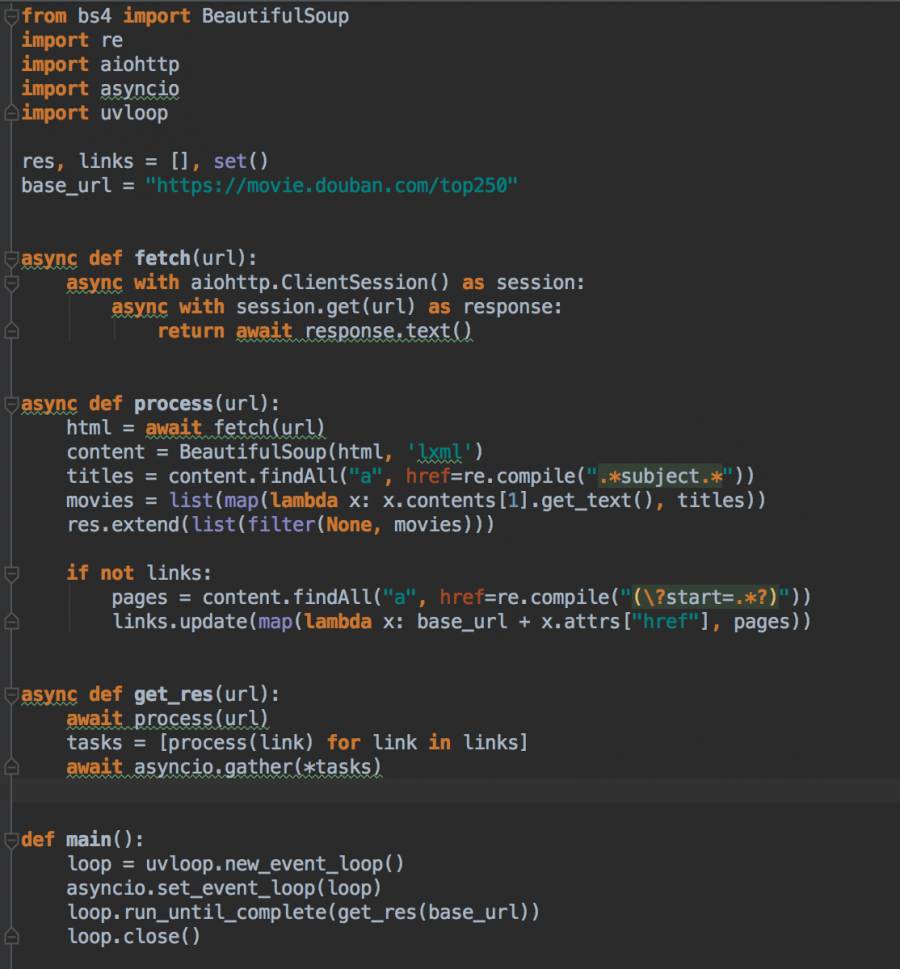
Python3异步编程
900x969 - 69KB - JPEG

Scrapy:python3下的第一次运行测试
640x281 - 23KB - JPEG

最后2小时,400人等你一起学习Python3网络爬虫
600x748 - 57KB - JPEG

最后2小时,400人等你一起学习Python3网络爬虫
600x311 - 34KB - JPEG
以上就是python3如何利用requests模块实现爬取页面内容的实例详解的详细内容,更多请关注php中文网其它相关
第二:了解Python中urllib库 Python2系列使用的是urllib2,Python3后将其全部整合打印爬取网页的各类信息
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存其实用python爬取网页很简单,只有简单的几句话
使用python3爬取html页面内容使用到的模块有 使用下面代码就可以获取到小说内容了,网站出于反爬考虑,把
这篇文章给大家通过实例讲解了Python爬取网页数据的步骤以及操作过程,有python3 import webbrowser,sys,
本文为大家讲解了使用Python从网上爬取(采集)特定属性数据其实用python爬取网页很简单,只有简单的几句话
python3,爬虫 不太会用这个编辑器,就把word截图过来了…. from bs4 import BeautifulSoup import urllib.
1#coding=utf-8 2 import requests 3 from http.cookiejar import CookieJar 4 s = requests.session()5
