
 手机网站
手机网站
手机网站
手机网站
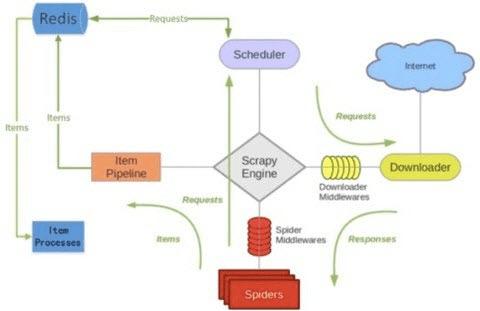
怎么样实现scrapy_redis爬虫分布式爬取功能?
480x311 - 17KB - JPEG
scrapy_redis获取英雄联盟数据,使用先列表页再
292x594 - 25KB - PNG
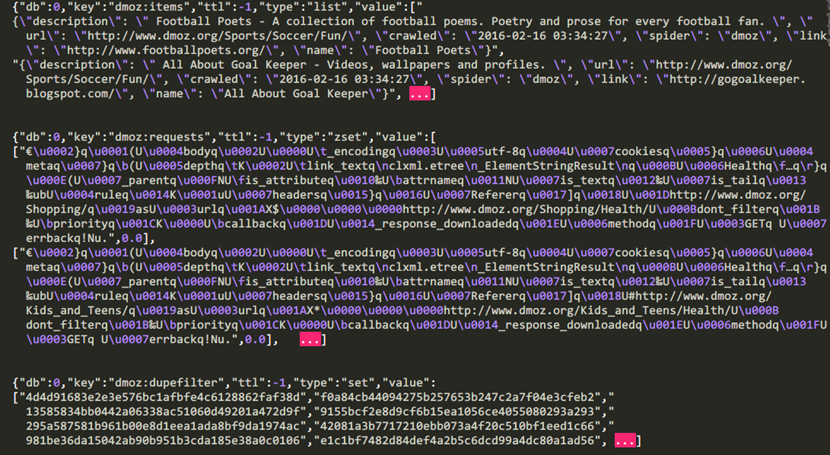
scrapy-redis使用详解 - kylinlin - 博客园
830x455 - 457KB - PNG
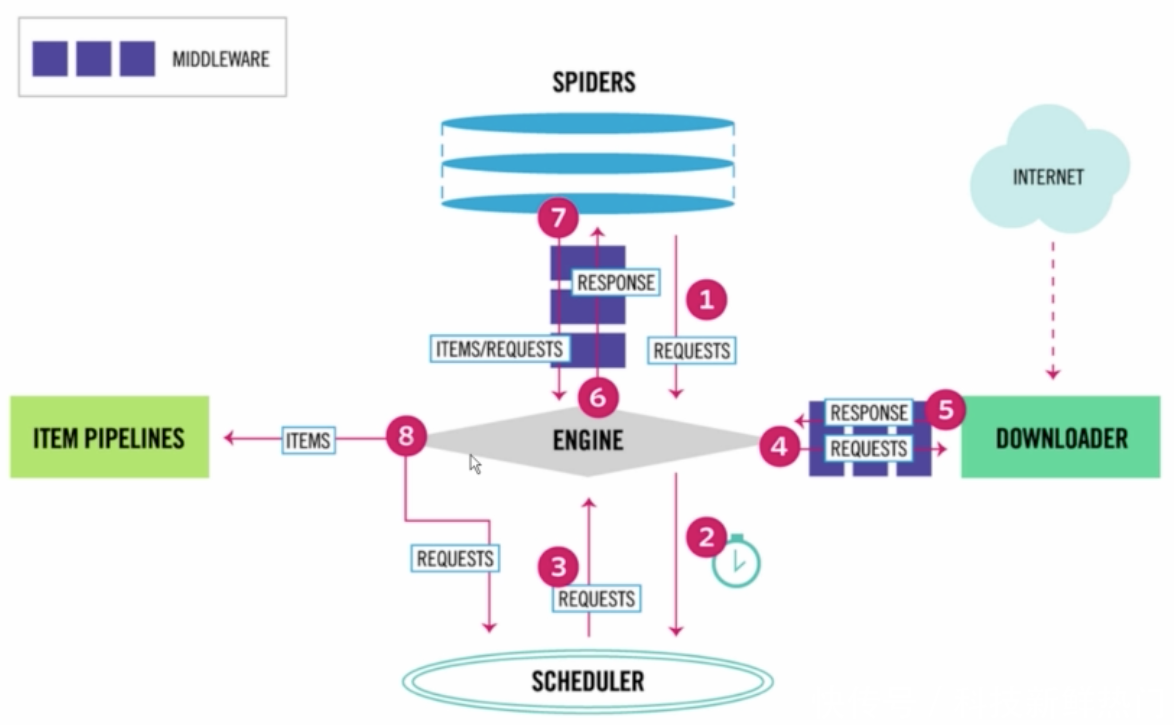
使用scrapy-redis框架实现分布式爬虫(1)!
1174x725 - 198KB - PNG

使用scrapy,redis,mongodb实现的一个分布式网
500x276 - 96KB - JPEG

Scrapy-Redis 详解
550x413 - 70KB - PNG

使用scrapy,redis, mongodb实现的一个分布式网
1121x517 - 246KB - PNG

Scrapy-Redis 详解
550x369 - 51KB - PNG

第9章 scrapy-redis分布式爬虫
476x260 - 18KB - JPEG
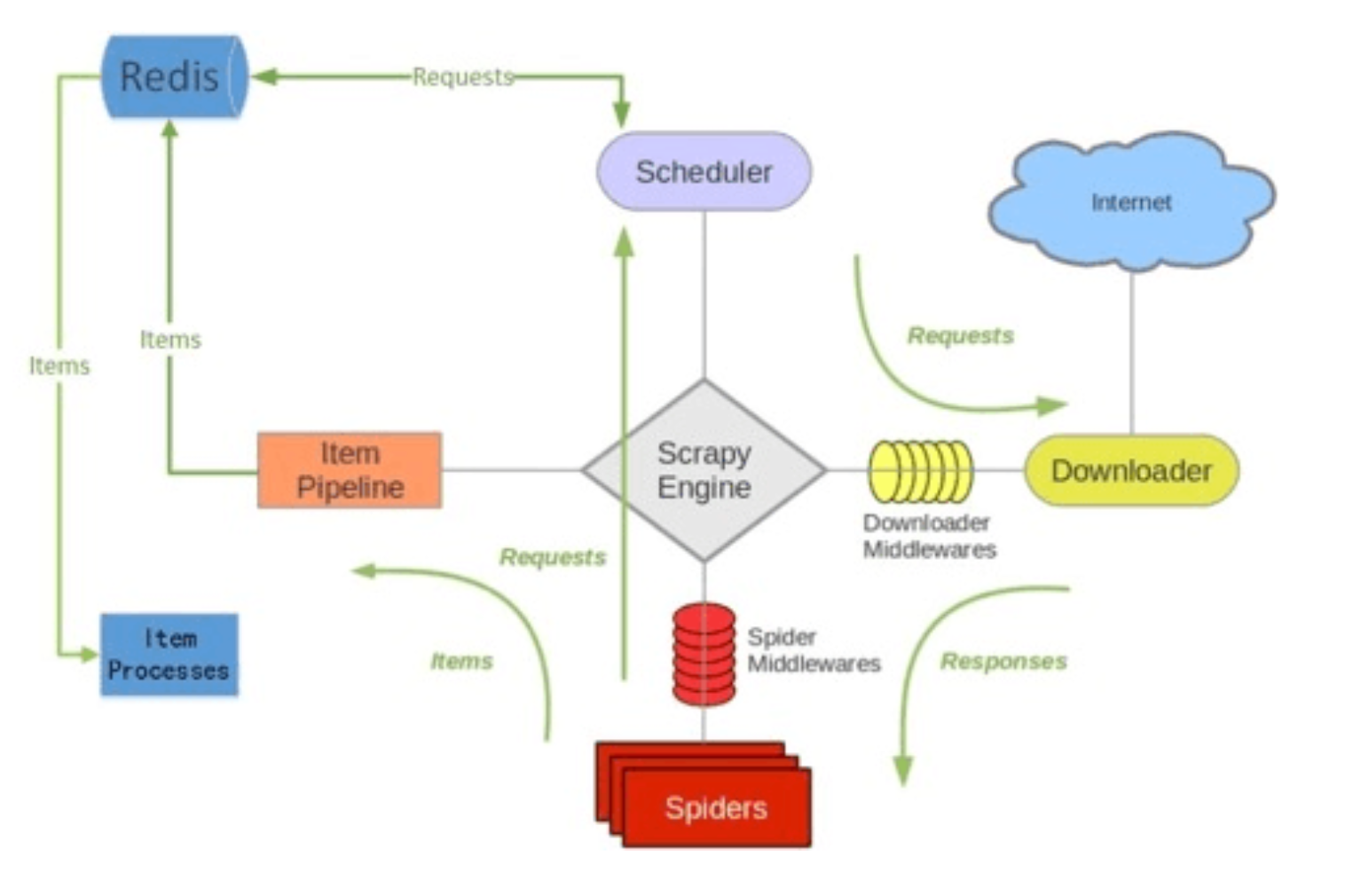
python--scrapy-redis分布式组件 - 想54256 - 博
1534x1010 - 572KB - PNG
使用scrapy,redis, mongodb实现的一个分布式网
1436x625 - 244KB - PNG

使用scrapy,redis,mongodb实现的一个分布式网
500x268 - 66KB - JPEG

scrapy-redis分布式爬虫启动为什么会等待
600x381 - 19KB - JPEG

scrapy-redis使用详解_NoSQL_第七城市
830x455 - 448KB - PNG

Scrapy+Redis+Mongodb爬取JD的商品评论
437x260 - 23KB - JPEG
redis.dupefilter.RFPDupeFilter",#'SCHEDULER':"scrapy_redis.scheduler.requests(self):startUrl=
同样的工程开 100 个进程,每个进程的 starturl 分别是 page/1,分布式(暂时还没涉及),redis,scrapyd
4scrapy阳光问政scrapy.Spider实现 5scrapy抓取阳光问政默认process_links 6scrapy抓取斗鱼直播的图片链接
day1│1爬虫的基本概念│2Fiddler简介│3网页信息简介│4读取网页三种方法│5正则表达式回顾│6抓取智联
工具包:request 爬取页面数据,然后redis 实现数据缓存,lxml 实现页面数据的分析,提取我们想要的数据,
redis.dupefilter.RFPDupeFilter",#'SCHEDULER':"scrapy_redis.scheduler.requests(self):startUrl=
同样的工程开 100 个进程,每个进程的 starturl 分别是 page/1,分布式(暂时还没涉及),redis,scrapyd
4scrapy阳光问政scrapy.Spider实现 5scrapy抓取阳光问政默认process_links 6scrapy抓取斗鱼直播的图片链接
day1│1爬虫的基本概念│2Fiddler简介│3网页信息简介│4读取网页三种方法│5正则表达式回顾│6抓取智联
3scrapy-redis案例简介 4scrapy-redis3个案例执行分析 5scrapy代码回顾 6scrapy-redis代码配置 7scrapy-
