
 手机网站
手机网站
手机网站
手机网站

web应用指纹识别之Scrapy介绍 - 软件工具 - 红
700x494 - 67KB - PNG

python scrapy的一点杂谈 - Python开发技术文章
831x544 - 19KB - JPEG
scrapy 实现去重,存入redis(增量爬取)
678x260 - 16KB - JPEG

scrapy 实现去重,存入redis(增量爬取)
300x260 - 9KB - JPEG
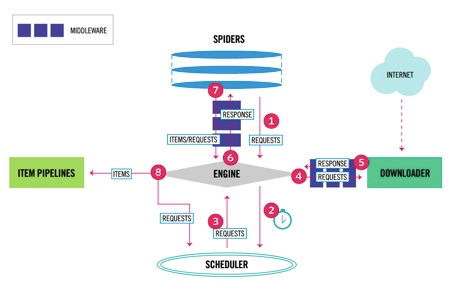
Python爬虫从入门到放弃(十二)之 Scrapy框架的
451x296 - 83KB - PNG

Scrapy利用Redis实现消重存入MySQL(增量爬
600x260 - 27KB - JPEG

Scrapy利用Redis实现消重存入MySQL(增量爬
678x260 - 98KB - PNG

Scrapy利用Redis实现消重存入MySQL(增量爬
322x260 - 31KB - JPEG

Scrapy爬虫原理及代码实例 - 云计算技术频道
700x494 - 93KB - PNG
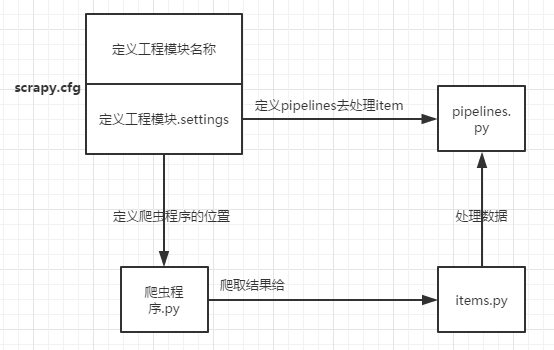
scrapy简单入门及选择器 - 孔扎根
554x350 - 23KB - PNG

Scrapy-redis爬虫分布式爬取的分析和实现_「
480x311 - 17KB - JPEG
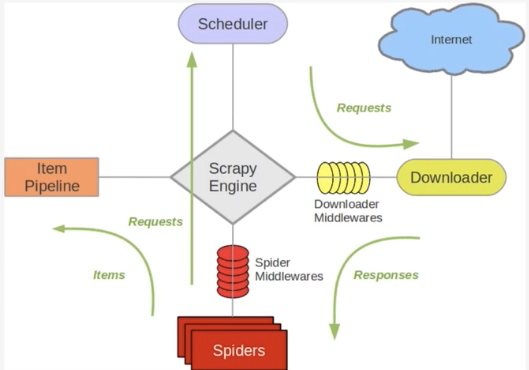
Python爬虫从入门到放弃(二十)之 Scrapy分布式
529x370 - 124KB - PNG
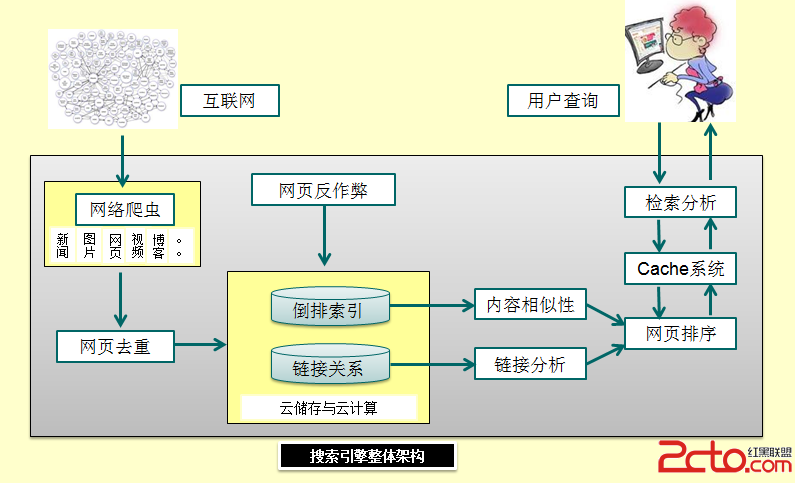
搜索引擎网页去重算法分析 - 百科教程网_经验
795x483 - 83KB - PNG

Python爬虫工程师必学的Scrapy分布式原理与分
640x402 - 28KB - JPEG

Python爬虫工程师必学的Scrapy分布式原理与分
541x347 - 13KB - JPEG
第二种就是scrapy内置的去重方案生成的指纹,这里我们点开源码会发现使.本文主要介绍爬虫收集数据优点、爬虫
1.需要将 dont_filter 设置为 False 开启去重,默认是 True,没有开启去调度器都会根据请求得相关信息加密
1.dont_filter默认为False,即开启去重;调度器都会根据请求得相关信息加密得到一个指纹信息,并且将指纹信息
scrapy的去重原理【知其然且知其所以然,才能够更好的理解这个框架,而且在使用和改动的时候也能够想出更
Scrapy有自动去重,它的去重使用了Python中的集合。那么要实现去重,这个指纹集合也需要是共享的,Redis
scrapy_redis工作原理:调度器将不再负责Url的调度,而是将url上传给redis组件会通过指纹(key)来进行
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本如何去重?
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取如何去重?
3.添加去重的class DUPEFILTER_CLASS="scrapy_redis.dupefilter.RFPDupeFilter"4.引入pipeline,并更改优先
