
 手机网站
手机网站
手机网站
手机网站

PySpark关于HDFS文件(目录)输入 数据格式的
712x263 - 76KB - PNG

hdfs datanode数据存储格式分析_服务器应用_
983x500 - 59KB - JPEG

1. Inceptor架构
600x391 - 30KB - PNG
基于 Hive 的文件格式:RCFile 简介及其应用 - 百
774x694 - 91KB - JPEG
基于 Hive 的文件格式:RCFile 简介及其应用 - 百
866x357 - 165KB - PNG

Hadoop上小文件存储处理
407x255 - 11KB - JPEG
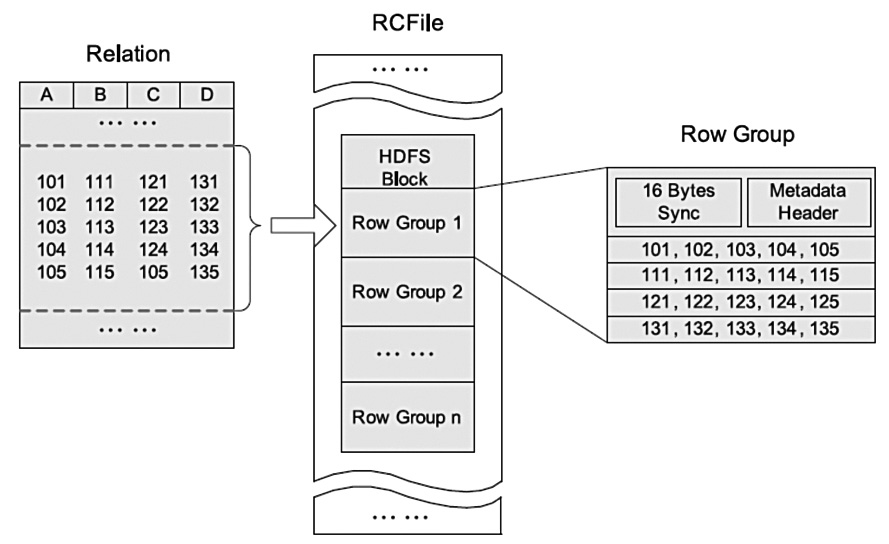
基于 Hive 的文件格式:RCFile 简介及其应用 - 百
889x544 - 94KB - JPEG

hive存储格式 - 其他综合 - 红黑联盟
643x576 - 126KB - PNG

hive存储格式 - 数据库其他综合 - 红黑联盟
771x323 - 145KB - PNG

SQL on Hadoop中用到的主要技术 - hdfs - 博客
979x464 - 104KB - JPEG
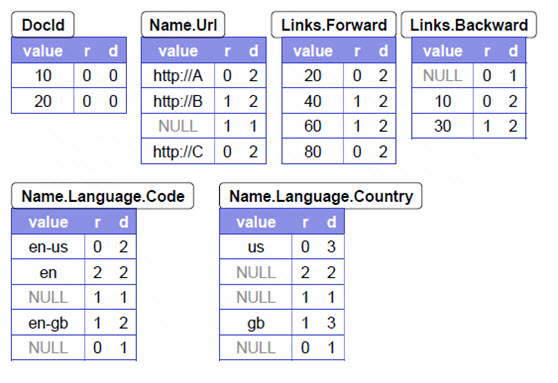
SQL on Hadoop中用到的主要技术 - hdfs - 博客
558x383 - 73KB - JPEG

列式存储 HBase 系统架构学习_「电脑玩物」
500x255 - 13KB - PNG

列式存储 HBase 系统架构学习_「电脑玩物」
500x275 - 22KB - PNG
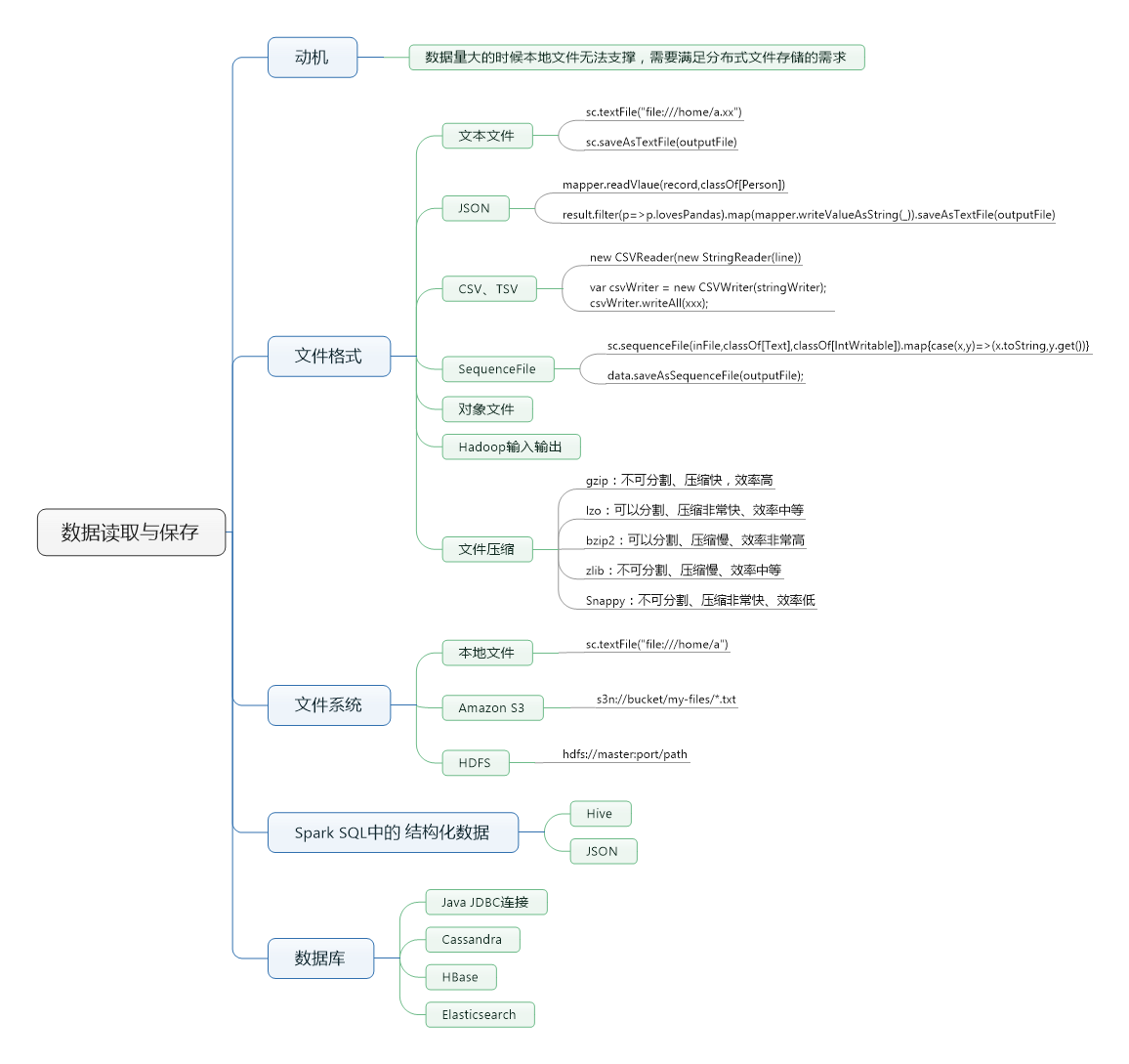
《Spark快速大数据分析》-- 第五章 数据读取和
1156x1089 - 160KB - PNG

uid 总结 Chapter 7 MapReduce的类型与格式 -
754x311 - 71KB - JPEG
那么这些数据除了用txt格式存放,还能以什么方式存放到hdfs?有谁试过吗?hdfs可以存储任何形式的文件啊。
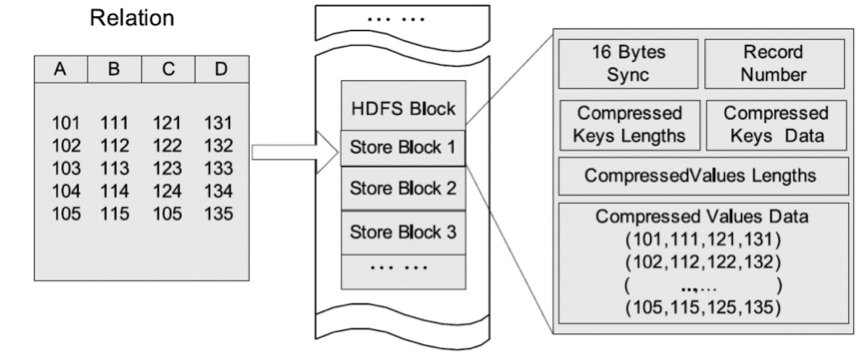
Hive默认格式,数据不做压缩,磁盘SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以,value>的
Parquet:Parquet 是面向分析型业务的列式存储格式,由 Twitter 和 Cloudera 一个 Parquet 文件是 由一个
由jazdbmin1639收集整理有关文件存储格式,hdfs文件存储格式的内容,包含有如何更改文件保存的默认格式哪些是
注意:使用MapFile或SequenceFile 虽然可以解决HDFS 中小文件的存储问题,但也有一定局限性,如:1.
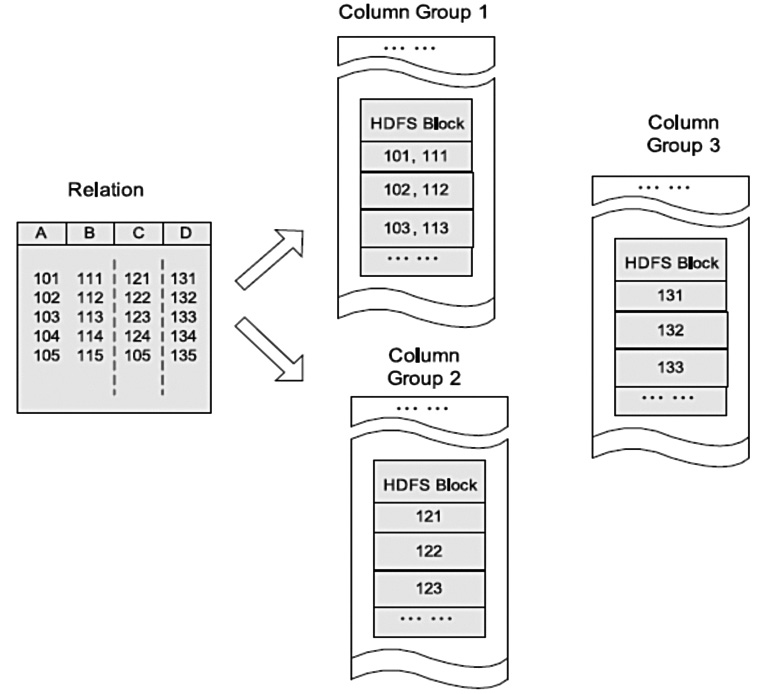
HDFS块内行存储的例子  HDFS块内列存储的例子  HDFS块内RCFileHDFS 文件格式—SequenceFile RCFile
根据是否压缩,以及采用记录压缩还是块压缩,存储格式有所不同: 不压缩: 按照文件存储大小比较与分析
以及采用记录压缩还是块压缩,存储格式有所索引作为一个单独的文件存储,一般每个128个记录存储一个索引。
