
 手机网站
手机网站
手机网站
手机网站

python抓取网页内容 - Python开发技术文章_教
1330x557 - 332KB - JPEG

Python3.4网页抓取之编码异常-Python-第七城市
700x457 - 66KB - JPEG

Python 爬虫网页抓图保存 - Python开发技术文章
788x588 - 152KB - PNG

WebSocket+多线程python socket网页版实时在
893x695 - 44KB - PNG
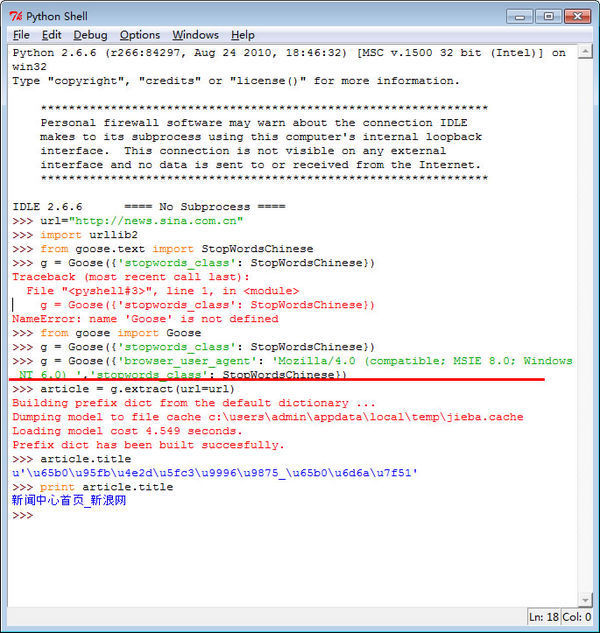
为什么用python-goose提取网页时有时候提取的
600x633 - 104KB - JPEG

Scrapy 爬虫框架爬取网页数据_Python_第七城
716x428 - 102KB - PNG
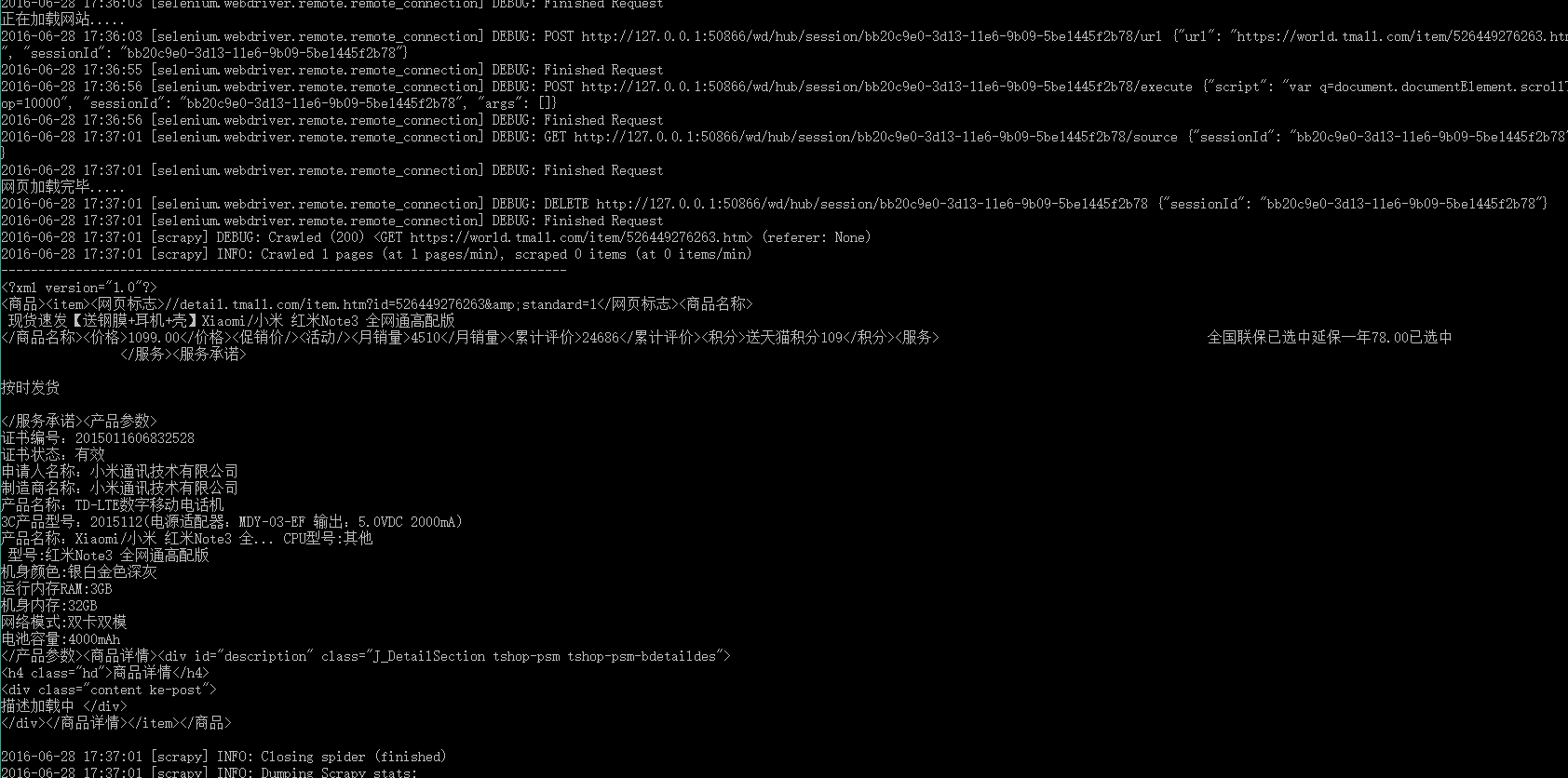
Python网页信息采集:使用PhantomJS采集淘宝
1684x836 - 48KB - PNG

Python网页信息采集:使用PhantomJS采集淘宝
640x360 - 20KB - PNG
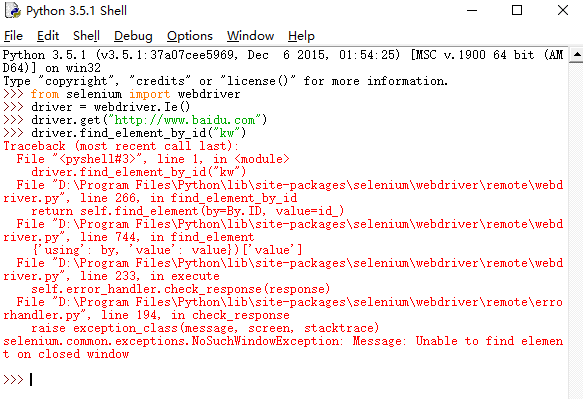
selenium自动化测试中,python脚本无法操作网页
583x399 - 11KB - PNG
![[原]Python网页编程(CGI)-Python-第七城市](http://www.th7.cn/d/file/p/2015/02/03/13fc3e29710407bb61c96f8ed97d2611.jpg)
[原]Python网页编程(CGI)-Python-第七城市
700x394 - 76KB - JPEG
![[原]Python网页编程(CGI)-Python-第七城市](http://www.th7.cn/d/file/p/2015/02/03/048a8fdc04e8f537a9fb6f45f8a47e0e.jpg)
[原]Python网页编程(CGI)-Python-第七城市
700x400 - 106KB - JPEG

Python网页小爬虫
227x225 - 7KB - PNG
[Python爬虫]使用Python爬取动态网页-腾讯动漫
462x383 - 45KB - JPEG
python如何在网页上的框里上传数据? - 计算机
768x670 - 220KB - PNG

用python做网页抓取与解析入门笔记-编程1000
587x390 - 16KB - PNG
我们没人会前端,所以最怕修改网页,一开始选择了Flask框架,我搞了半天遇到各种坑(还要 一句话安装完。怎么算成功呢?可以直接在写的python里import django 没报错就成功,数
原 Python实战1_1:做一个自己的网页 Little_Blue_Eye 阅读数:22994 2016-06-22 版权声明:本文为博主原创文章,若转载请标注本文地址 参加了Python实战课程,此为第一节课的
E:\mysite python manage.py runserver Performing system checks. System check identified no issues (0 silenced). You have 14 unapplied migration(s). Your project may not work
使用python访问网页 2018年03月28日 14:40:14 win9zz阅读数:7189 版权声明:本文为博主原创文章,未经博主允许不得转载。 python版本:3 import urllib.request url= req=urllib.re
使用python Django做网页的步骤 1 、创建一个django项目 使用django-admin.py startproject MyDjangoSite 参考这里 2、建立视图 from django.http import HttpResponsedef hello(request): return HttpResponse("我的第一个简单的python django项目。") 3、修改urls.py 我们为urlpatterns加上一行: (r'^hello/$', hello), 这行被称作URLpattern,它是一个Python的元组。元组中第一个元素是模式匹配字符串(正则表达式);第二个元素是那个模式将使用的视图函数。 正则表达式字符串的开头字母"r"。 它告诉Python这是个原始字符串,不需要处理里面的反斜杠(转义字符)。一般在使用正则前加入"r"是一个好的习惯! 4、运行python manage.py runserver http://127.0.0.1:8000/hello
用BeautifulSoup处理解析网页,import后,一切从soup = BeautifulSoup(webpage.read( ))开始,你可以用python的终端自己玩玩这个产生的soup对象。我这里就说下一种我比较喜欢
常见的python网页解析工具有:re正则匹配、python自带的html.parser模块、第三方库BeautifulSoup(重点学习)以及lxm库。 2、常见网页解析器分类 以上四种网页解析器,是两种
工具/原料Pythonrequests库方法/步骤1:演示代码如下,在爬取中文网页时,会发现返回结 以上代码在python3中测试。Py3.X源码文件默认使用utf-
推荐Django框架,豆瓣阅读上有一个免费的入门教程:Django入门教程 以及The Django Book中文版都是不错的参考资料。 Django非常好上手,内置了许多常用的功能。Django的Admin系统更是Django的几大killer feature之一。 网页端的话,还是要学一下HTML/CSS/js的。 如果你想快速上手做东西,推荐Bootstrap + jquery的组合,对于非专业开发来说,效率非常高。
